2023 in SEO with Data Science
- Well it's 2023
- SEO in 2023: A Data Science Approach
- The question
- Getting the data
- Using Horseman
- Processing the data
- Answering Other Questions
- Content Analysis
- LDA Analysis
- What are the most common words in the listicles?
- I trained GPT-2 on the listicles and all I got was this lousy text
- What are the biggest SEO trends of 2023?
Well it's 2023 #
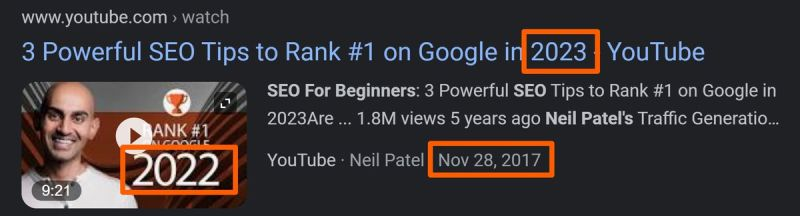
I've been using Horseman, the tool developed by Chris Johnson for a couple of long term projects right now. Because I've been using it so much, I ended up kind of going down a rabbit hole. And that rabbit hole is the question of "what are the clickbait SEO trends of 2023?"
My mission was simple: get data, process it, and visualize the results. I'm going to show you how I did it, and what I found.
Also it's perfectly reasonable and smart for me to put this out in April, months after the year has started, during BrightonSEO, aka the week that nobody reads articles. I'm a smart guy.
SEO in 2023: A Data Science Approach #
The question #
What is SEO in 2023? Are people just regurgitating the same old SEO trends, or are they actually doing something new? I wanted to find out.
Getting the data #
The first step was of course: how get data? Well, this is for SEO, so obviously any SEO or SEO agency worth their salt would show up for a series of queries like "seo in 2023", "top * in SEO in 2023", and so on. After... analyzing... the Google results, I had a series of web pages with titles like "Is SEO Still relevant in 2023?", "SEO in 2023", and "15 SEO Trends for 2023 That You Need to Know." I ended up with around 1200 webpages, which I then used Horseman to scrape the data from.
Using Horseman #
Horseman is a tool that allows you to crawl websites. It's a bit like Scrapy, but it's a lot easier to use, and a lot more customizable. I used several Horseman features to make my life a lot easier.
- List Crawls
Starting with the most basic thing, I dragged my list of URLs over to the crawler and let it do its thing. This is the most basic way to use Horseman, and it's great for getting started. But before I started my crawl off, I enabled a couple of other features:
- Custom Snippets
Horseman allows you to create custom JS snippets-- this lets you do things like scrape data from a page using CSS selectors, or even use Regex. I created a custom snippet that would find any list elements on the page and surface them in an "explore" node, letting me see the number of results as a cell, and get the list items as a list.
/* horseman-config enable-explore */
var list_items = []
var list_numbers = []
// Get all the <ol> elements
var ordered_lists = document.querySelectorAll('ol')
// Loop through the <ol> elements
for (var i = 0; i < ordered_lists.length; i++) {
var list_items_temp = ordered_lists[i].querySelectorAll('li')
for (var j = 0; j < list_items_temp.length; j++) {
list_items.push(list_items_temp[j].textContent)
list_numbers.push(j + 1)
}
}
const zip = (a, b) => a.map((k, i) => [k, b[i]]);
const extended = zip(list_numbers, list_items)
extended.unshift(['number', 'item'])
return {
cell: list_items.length,
extended: extended
}This resulted in me being able to analyze my results in a dataframe, in much finer detail. Another useful tool for this came from:
- Pre-built Snippets
The content extractor tool in Horseman is legitimately so useful for any sort of NLP work. It uses Mozilla's Readability library to extract the main content from a page, which avoids a lot of the work and messiness of trying to do it yourself. I used this to extract the main content from each page, which let me go HAM on the NLP.
Additionally, Horseman has added an update allowing you to use GPT to generate snippets and analyze results. Basically automating a ton of the work I had to do on this project. I'm going to be using this a lot more in the future!
Processing the data #
I ended up with a dataframe that looked like this:

And a smaller dataframe of the lists I found, which looked like this:

Hooray! This is a ton of data, and I'm going to use it to answer my question: what are the clickbait SEO trends of 2023?
Answering Other Questions #
First off, the question all SEOs want the answer to: who is ranking the best? I used python to group together the sites by domain, and then sort them by the number of times they appeared in the list. This is what I got:
| Domain | Count |
|---|---|
| searchengineland | 8 |
| neilpatel | 6 |
| 6 | |
| semrush | 6 |
| quora | 5 |
Themes in articles by Ranking #
I'm a huge dummy who totally forgot to get ranking data for these articles. :)
This is a pretty good list of sites that are ranking well for these queries. But what about the actual content? I used the content extractor to get the main content of each page. And then I performed ** Content Analysis**.
Content Analysis #
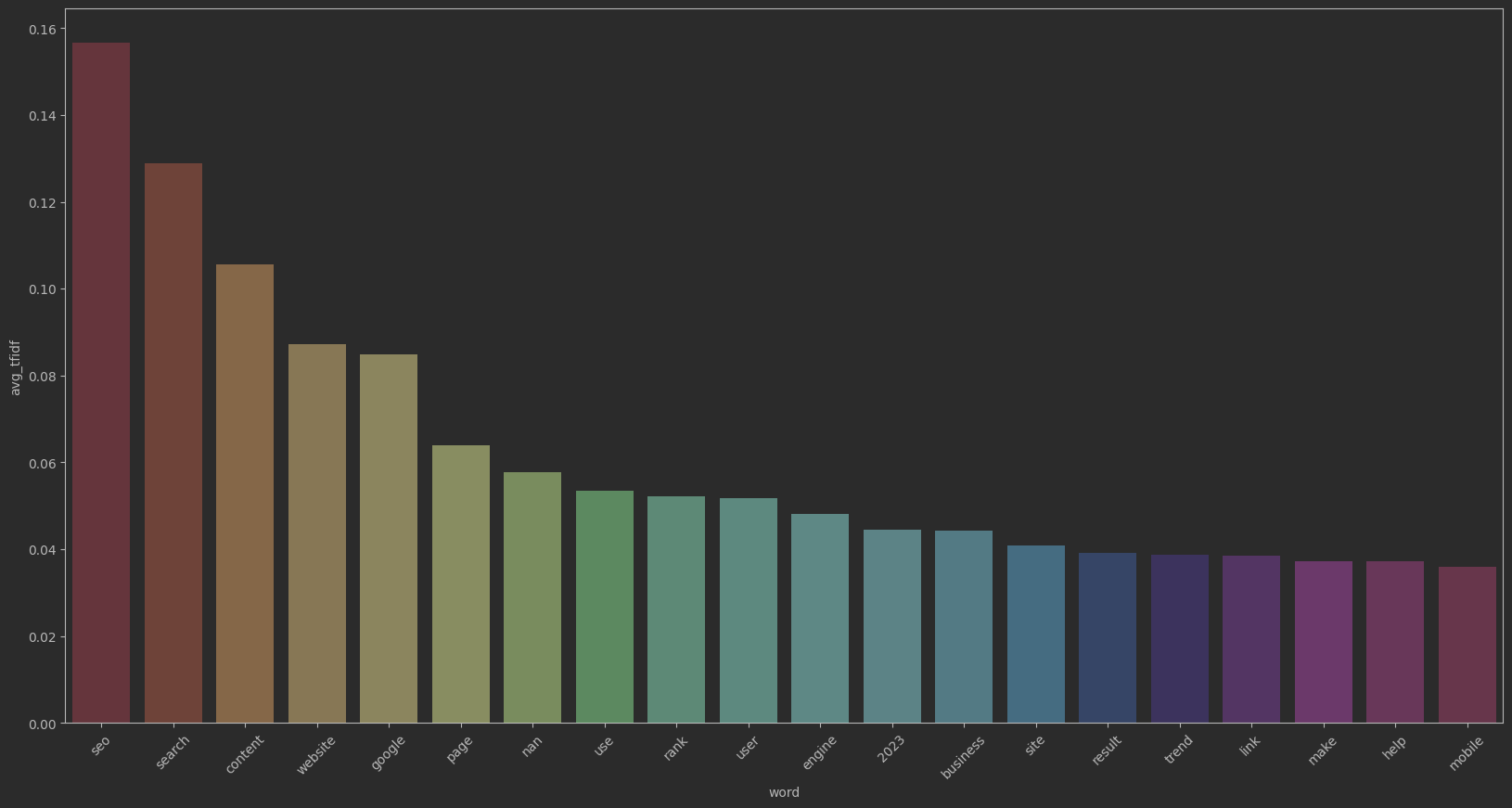
The first thing I did was run a TF:IDF on Tokenized versions of the content. This is a pretty standard NLP technique, and it's a good way to get a sense of what the content is about. I used the sklearn library to do this. Here's what I got:
Most common words:
| Term | TF:IDF |
|---|---|
| seo | 0.15667343334114228 |
| search | 0.1288146205263499 |
| content | 0.10558588226854985 |
| website | 0.08727725933116887 |
| 0.08485584111062101 | |
| page | 0.06399707298061438 |
| use | 0.05340342917433483 |
| rank | 0.0522176555322365 |
| user | 0.051743382749767974 |
| engine | 0.04804653913753525 |
| 2023 | 0.044486084565650834 |
| business | 0.04420586605084493 |
Extremely expected results! Obviously SEO is showing up the most, but it's interesting to see that "content" is also showing up a lot. This is probably because a lot of the sites are talking about "making good content", which I've heard is pretty important for SEO.
From the top terms according to TF:IDF, I then went through the content and found the URLs that had the highest TF:IDF score for those terms. Here are the top 5:
I also made a pretty chart:
I then created a correlation matrix to see which terms were most correlated with each other. This is a good way to get a sense of what the content is about. Here's what I got:
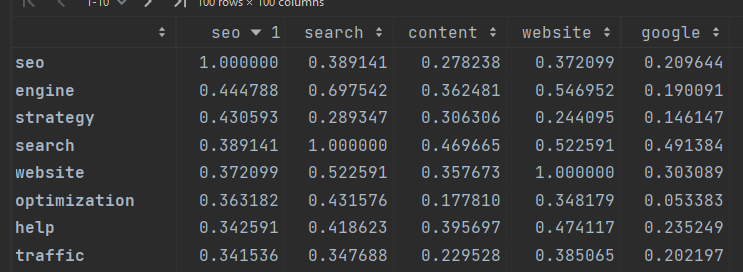
Most Correlated Terms:
| Term 1 | Term 2 | Correlation |
|---|---|---|
| keyword | research | 0.7088162072499519 |
| answer | question | 0.7085250840943669 |
| search | engine | 0.697542025816511 |
| result | search | 0.6756680640179428 |
| user | experience | 0.6433130313063918 |
And some of the least....
| Term 1 | Term 2 | Correlation |
|---|---|---|
| page | 2023 | -0.11849038814229622 |
| link | 2023 | -0.11255929533338599 |
| research | 2023 | -0.10519903223453184 |
| tool | 2023 | -0.09822451703558555 |
| post | 2023 | -0.09758735465671813 |
| website | 2022 | -0.049466669813944014 |
| engine | 2022 | -0.04861868642233016 |
| best | 2022 | -0.04648097430475952 |
Below in the iframe, you can explore some of this correlation data:
Out of the top 100 terms, for example, "rank" was most highly correlated with the term "high" and least correlated with the term "SEO."
Meanwhile, "research" was the least correlated with the term "2023". I'll let you know if that seems portentous.
I also ran a sentiment analysis on the content, using the TextBlob library. This is a pretty simple library, but it's a good way to get a sense of the overall sentiment of the content. Here's what I got:
Pages with the most positive sentiment:
And the most negative:
I think one of the things that's interesting about this kind of analysis is how you can see how flawed it can be while still getting an overview of the results.
Clustering by Number in the listicle: #
SEOs love listicles: they're the backbone of the web. Buzzfeed etc. So I wanted to cluster and look at, in these listicles, which terms were most common in the first place, second place, etc.
Using Horseman, I extracted different "places" in the listicle versions of the articles, 1-10 and 11+. I then used the KMeans clustering algorithm to cluster the articles using these numbers: basically, clustering everything in a listicle that was in first place, second place, etc. together.
I first figured it'd be prudent to ignore stopwords and some of the most common words, see below:
stop_words = set(stopwords.words('english'))
ignore_list = ['seo', 'search', 'optimization']And these are my results!
| Position | Top Terms |
|---|---|
| 1 | content, quality, voice |
| 2 | mobile, content, voice |
| 3 | voice, content, mobile |
| 4 | content, voice, mobile |
| 5 | user, local, content |
| 6 | video, content, local |
| 7 | content, video, local |
| 8 | content, video, social |
| 9 | local, snippets, content |
| 10 | content, social, media |
| 11+ | site, learning, content |
I reran this again, this time ignoring "content", "quality", "user", "site", "voice", and "mobile" as well, to see if I could get some more variety in the results:
| Position | Top Terms |
|---|---|
| 1 | keyword, experience, focus |
| 2 | keywords, google, website |
| 3 | experience, google, website |
| 4 | experience, website, mobile |
| 5 | experience, local, website |
| 6 | video, artificial, local |
| 7 | video, local, experience |
| 8 | video, social, media |
| 9 | local, google, building |
| 10 | video, social, media |
| 11+ | social, machine, learning |
I used this colab to do some visualization of the clustering.
So here's another embedded iframe to play with:
LDA Analysis #
If you read my NLP Article for OnCrawl you probably read a little about LDA analysis.
LDA began as a way to analyze genetics: it's a way to look at a bunch of different genes and figure out what they have in common. Similarly, it's used in ML and text analysis to look at a bunch of different documents and figure out what they have in common.
You can explore the LDA analysis for this topic map here:
Named Entity Recognition #
I used Spacy to do some named entity recognition on the content. This is a way to extract entities from text, like people, places, and organizations.
import spacy
nlp = spacy.load('en_core_web_sm')
# Define a function to extract entities from text
def extract_entities(text):
doc = nlp(text)
entities = [ent.text for ent in doc.ents if ent.label_ in ['ORG', 'PERSON']]
return entities
# Apply the function to each column of the dataframe
for column in df1.columns:
entities = []
for text in df1[column].dropna():
entities += extract_entities(text)
entities = list(set(entities)) # Remove duplicates
print(f"Entities in {column}: {', '.join(entities)}")
And here are the results:
| Positions | Entities |
|---|---|
| 1 | Google Ads, Organic Search, SERP Optimization for Brands, Interactivity, Safe Browsing, Structured, Knowledge Graphs, Long-Tail Keywords, Video Content, Cumulative Layout Shift, Developing Customer Personas, Improve Page, Voice, Voice Search Optimization, Artificial Intelligence, SERP Features, Lifetime Value, Know Your Metrics & Set Goals, BERT Update, LSI, YouTube, Featured Snippets, Passage Indexing, Organic Traffic -, Mobile Responsive Web Design, HTTPS, Machine Learning, GPT3, AI, SERP Layout, Image Optimization for SEO, Mix, Schema Markup, Google's Shopping Graph, Social Signals, A.I. Content Identification Dilemma Will Persist, Online Shopping Optimization, TikTok, Google, Videos, Un, SERP, CTR, Artificial Intelligence, Trustworthiness (EAT, Schema markup, Intrusive Interstitial, EAT, Backlinks, ABA, API, Modify, Panda, Mobile Optimization, Local SEO, dan Google Ads, User Intent, Evaluate, EEAT, schema markup, GPA, Более, UX, Enhanced Security, Artificial Intelligence and Machine Learning, Keyword Difficulty, Entities, Voice Search Optimization, AI-Powered Optimization, First Indexing, Importance of Keyword Research, Structured Data, Functionality, CALM, Google SEO, Long-Form Information, Google Discover, Mobile-Optimization, First Input Delay, Focus on Local SEO, Keyword, A.I. Information, Loading, Mobile-First Indexing, Mobile Optimization, Optimiser, Voice Search Optimisation, RankBrain |
| 2 | New Local SEO Strategies, Mobile-First Indexing and Optimization, Backlinks, Core Web Vitals Report, Structured, User Intent and Natural Language Processing, para pesquisa visual, Google Business Profile, Rich Pins, Conversational Queries and User Intent, Artificial Intelligence (AI, Machine Learning, Page Speed, Google Discover, AI, meta tags, Обсуждение, Conversational AI, Dominate - Relevant, Core Web Vitals, Instagram, Google's, Google E-A-T, Voice, Emphasis on Local Search, Keyword Suggestions, Audience-Targeted, como imagens, The Rise of Voice Search Optimization, schema markup, TikTok, AI-Driven Content Writing, SeoStack Keyword Tool, Bard AI, Emphasis on Local SEO, Keyword, FAQ, Google, Voice-Based Search Begins, SMO, Artificial Intelligence and Machine Learning, UI/UX Factors, NLP, Mobile-First Indexing, BI, Créer un contenu pertinent et riche sémantiquement, SERP, EliteSEO, My Business, Artificial Intelligence, LSI, Mobile Optimization, Voice Search Optimization, geo-targeted, Content marketing & SEO, Saran Kata Kunci, Social Media Optimization, EAT, RankBrain, Amazon, Google Featured Snippets & People Also Ask |
| 3 | Optimising Images for SEO, YMYL, the Hub & Spoke Model, GPT-4, SERP Optimization for Brands, Bing, Share Buttons, Structured, Google Business Profile, Artificial Intelligence (AI, Integration of Voice Search, MUM, Keyword Targeting, Google Discover, Javascript, stratégie de longue, SSL, AI, Pro-Audience, Microsoft, E.A.T., API IndexNow, Organic Search Data Are Dependent, Emphasize Quality Content, Universal Analytics, Core Web Vitals, Instagram, Google's, Voice, Google Algorithm, AI SEO, Google Search, Authoritativeness, Trustworthiness, Mobile-First Indexing and Mobile Optimization, TikTok, Mobile SEO, Augmented Reality & AI, Markup, Google My Business, Keyword, Google, Videos, Artificial Intelligence and Machine Learning, Mobile-First Indexing, AMP, SERP, My Business, CTR, PPC, Mobile Optimization, Google Adwords, YouTube, The Importance Of User Experience Will Be Greater Than Ever, Voice Search Optimization, Mobile Optimization & AMP, AI Content, Schema markup, EAT, gegenereerde afbeeldingen, Emphasis on Author Authority |
| 4 | Featured, the Google Business Profile, Structured Data, Zorg, Backlinks, Machine Learning Integration, CIS, Mobile & voice search, Ebay, Structured, Artificial Intelligence (AI, Pins, Machine Learning, Bing Image Creator, AI, kan hierop inspelen, Digital, Focus on Quality Content, Schema Markup, Mobile-First Indexing for Small Screen Users, ML, Artificial Intelligence & Machine Learning, Jak sprawić, para personalizar, Etsy, schema markup, Twoja, Accelerated Mobile Pages, Mobile, SeoStack Keyword Tool, Faster Websites, Google My Business, Keyword, Artificial Intelligence (AI) Will Play a Larger Role, Google, Videos, Optimize For Voice Search: Learning, Page Types, Artificial Intelligence and Machine Learning, Борьба, Google AMP, Mobile-First Indexing, NAP, Embrace AI, markup, Siri, AMP, Mobile-First Indexing: With more and more, CTR, Authority, Mobile Optimization, Trustworthiness (EAT, Featured Snippets, YouTube, Alexa, Voice Search Optimization, Google My Business optimization, EAT, the Overall Content Landscape Within Your Industry, Amazon, Omni-channel, the Google Title Update |
| 5 | Google Ads, Yandex, Backlinks, Review Snippet, Structured, HTTPS, Artificial Intelligence (AI, Google My Business Optimization, Backlinks - These, User Intent Optimization, Artificial Intelligence/Machine Learning, Machine Learning, Ranking Factor, Google Discover, AI, Schema Markup, Perhatikan, Improve Page Speed, ML, un, Voice, Better Focus on User Intent, Authority, Relevance, Trust & Diversity, Allouer, Optimize For Mobile Design, Build Local Links, schema markup, Voice Search Optimization Will Be Critical, Google Maps, Keyword, Google, UGC, Tingkat Kesulitan Kata Kunci, Keyword Difficulty, Mobile-First Indexing: Optimizing websites for mobile devices, Amazon Affiliates, Keyword Search Results, TechRadar, CTR, Featured Snippets, Voice Search Optimization, Schema markup, Google My Business optimization, Click Through Rate, Deliverables, metadata, Reduce Crawling, TODOS |
You can explore the most common entities by type of entity in the below iframe: obviously, Google and AI are the most common entities throughout these lists.
Hot Topic Mentions by Place in the listicle: #
Hot takes are for now: Google, AI, and Mobile-First Indexing are forever. One thing I thought would be fun to look at is how the hot topics are mentioned in the listicles. I used the same method as above to count the number of times each hot topic was mentioned in each listicle. I then plotted the results in a heatmap to see how often certain topics show up at certain points.
import pandas as pd
# Define the terms of interest
terms = ['AI', 'artificial intelligence', 'ML', 'Mobile', 'Content', 'Links', 'Visual', 'Voice']
# Iterate over the columns of df1
results = []
for col in df1.columns[1:]:
col_docs = df1[col].astype(str).tolist() # Extract the documents in the column
col_total = len(col_docs) # Calculate the total number of documents in the column
term_counts = [sum([term.lower() in doc.lower() for doc in col_docs]) for term in terms] # Count the number of documents that mention each term
term_percents = [count / col_total * 100 for count in term_counts] # Calculate the percentage of documents that mention each term
for term, percent in zip(terms, term_percents):
results.append({'Column': col, 'Term': term, 'Percentage': percent}) # Store the result in a dictionary
# Display the results in a table
results_df = pd.DataFrame(results)
print(results_df)
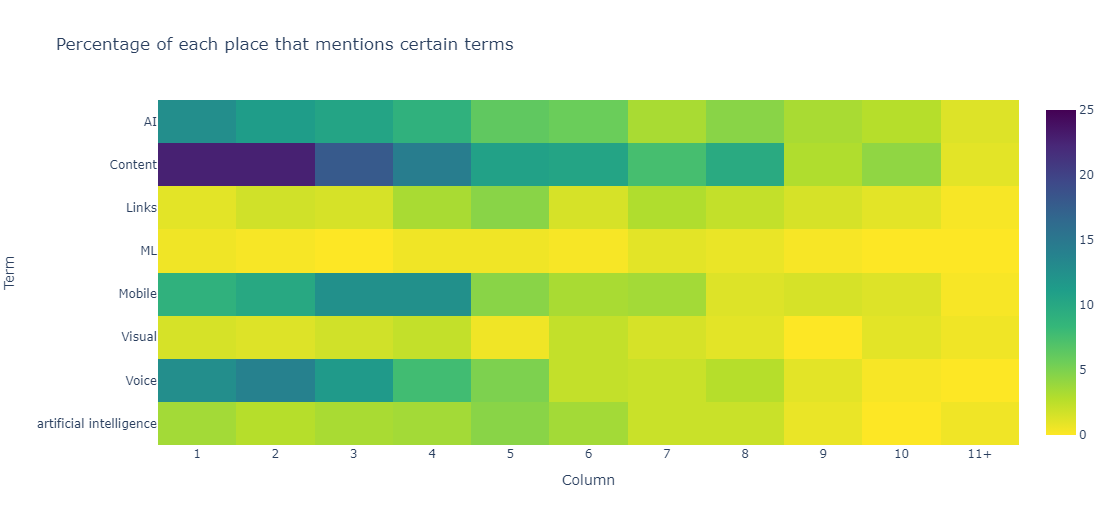
| Term | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11+ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AI | 12.718204488778055 | 11.221945137157107 | 10.473815461346634 | 8.977556109725686 | 6.234413965087282 | 5.7356608478802995 | 3.2418952618453867 | 4.488778054862843 | 3.2418952618453867 | 2.7431421446384037 | 1.2468827930174564 |
| Content | 22.693266832917704 | 22.693266832917704 | 17.955112219451372 | 14.463840399002494 | 10.723192019950124 | 10.473815461346634 | 7.4812967581047385 | 9.72568578553616 | 2.9925187032418954 | 4.239401496259352 | 0.997506234413965 |
| Links | 0.997506234413965 | 1.7456359102244388 | 1.4962593516209477 | 3.2418952618453867 | 4.488778054862843 | 1.4962593516209477 | 2.9925187032418954 | 2.2443890274314215 | 1.4962593516209477 | 0.997506234413965 | 0.24937655860349126 |
| ML | 0.4987531172069825 | 0.24937655860349126 | 0.0 | 0.4987531172069825 | 0.4987531172069825 | 0.24937655860349126 | 0.997506234413965 | 0.7481296758104738 | 0.24937655860349126 | 0.0 | 0.0 |
| Mobile | 8.977556109725686 | 9.975062344139651 | 12.468827930174564 | 12.468827930174564 | 4.488778054862843 | 3.2418952618453867 | 3.4912718204488775 | 1.2468827930174564 | 1.4962593516209477 | 1.2468827930174564 | 0.24937655860349126 |
| Visual | 1.4962593516209477 | 1.2468827930174564 | 1.7456359102244388 | 2.2443890274314215 | 0.4987531172069825 | 2.2443890274314215 | 1.4962593516209477 | 0.997506234413965 | 0.0 | 0.997506234413965 | 0.4987531172069825 |
| Voice | 12.718204488778055 | 13.96508728179551 | 11.471321695760599 | 7.73067331670823 | 4.987531172069826 | 2.2443890274314215 | 1.99501246882793 | 2.7431421446384037 | 0.997506234413965 | 0.24937655860349126 | 0.0 |
| artificial intelligence | 3.4912718204488775 | 2.7431421446384037 | 3.2418952618453867 | 3.4912718204488775 | 4.488778054862843 | 3.4912718204488775 | 1.99501246882793 | 1.99501246882793 | 0.7481296758104738 | 0.0 | 0.4987531172069825 |
AI, Content, and Voice remain pretty strong: mentions of Links are way down. It's a bit cheap of me to put ML, AI, and Artificial Intelligence as three different things, but I was really curious to see what way people were talking about AI. It looks like they're talking about it mostly as a buzzword IMO.
What are the most common words in the listicles? #
| Term | 1 | 10 | 11+ | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| intent | 9.0 | 0.0 | 0.0 | 10.0 | 8.0 | 2.0 | 4.0 | 1.0 | 0.0 | 1.0 | 0.0 |
| Local | 9.0 | 5.0 | 0.0 | 11.0 | 12.0 | 9.0 | 31.0 | 16.0 | 14.0 | 5.0 | 6.0 |
| high | 9.0 | 2.0 | 0.0 | 11.0 | 10.0 | 17.0 | 9.0 | 3.0 | 5.0 | 3.0 | 1.0 |
| Experience | 9.0 | 0.0 | 0.0 | 3.0 | 6.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| ranking | 8.0 | 1.0 | 0.0 | 10.0 | 5.0 | 4.0 | 7.0 | 3.0 | 2.0 | 2.0 | 2.0 |
| Video | 8.0 | 6.0 | 0.0 | 5.0 | 6.0 | 11.0 | 11.0 | 8.0 | 14.0 | 9.0 | 3.0 |
| updates | 7.0 | 0.0 | 0.0 | 1.0 | 1.0 | 3.0 | 0.0 | 0.0 | 2.0 | 2.0 | 1.0 |
| tail | 7.0 | 0.0 | 0.0 | 8.0 | 8.0 | 2.0 | 0.0 | 1.0 | 1.0 | 2.0 | 0.0 |
| engine | 7.0 | 1.0 | 1.0 | 5.0 | 6.0 | 5.0 | 4.0 | 2.0 | 6.0 | 4.0 | 2.0 |
| AI | 7.0 | 1.0 | 2.0 | 13.0 | 8.0 | 7.0 | 4.0 | 3.0 | 3.0 | 3.0 | 1.0 |
| content | 62.0 | 7.0 | 2.0 | 73.0 | 51.0 | 31.0 | 28.0 | 31.0 | 24.0 | 27.0 | 8.0 |
| results | 6.0 | 1.0 | 0.0 | 9.0 | 8.0 | 9.0 | 2.0 | 6.0 | 5.0 | 6.0 | 2.0 |
| traffic | 6.0 | 1.0 | 0.0 | 3.0 | 8.0 | 2.0 | 2.0 | 4.0 | 5.0 | 1.0 | 3.0 |
| Technical | 6.0 | 3.0 | 2.0 | 2.0 | 3.0 | 2.0 | 1.0 | 2.0 | 5.0 | 0.0 | 3.0 |
Most common words in position 1 of the listicles:
content 62
Voice 38
Mobile 22
Position 2:
content
Voice
keywords
Position 3:
content
Voice
Mobile
So clearly, SEOs this year think that content, Voice, and Mobile are the most important things to focus on. Time for my opinion: if you don't already have a mobile friendly site, don't worry about it. you know? It's 2023.
Wordclouds by Number in the listicle: #
Wordclouds. Does anybody love them? Clients do, sometimes.
Most common words in position 1 of the listicles:
Most common words in position 2 of the listicles:

Most common words in position 3 of the listicles:

Most common words in position 4 of the listicles:

And these are the most common words in positions 11+:

I trained GPT-2 on the listicles and all I got was this lousy text #
sess = gpt2.start_tf_sess()
gpt2.finetune(sess,
dataset=file_name,
model_name='124M',
steps=2000,
restore_from='fresh',
run_name='run2',
print_every=10,
sample_every=200,
save_every=500
)
I slammed all the content into GPT-2 and let it train for a while. Here's what it came up with:
In search engines, SERPs increase with the user’s willingness to engage with different content sources, from articles and blogs to blog posts and blogs. As these types of content are being searched, it’s a good idea to optimize your content for that type of search.
Search engines also rank pages based on factors such as keywords, ranking difficulty, and quality. As this type of content helps users find the right content, it should be optimized and optimized for organic search.
To make sure that your website ranks well in search engines, remember that it doesn’t necessarily mean that every keyword you have is the same, but rather that it’s a reflection of the content people are searching for.
What do you need to know about the different types of search results?
- Types of search results on Google
Google’s search engine is constantly changing. Its algorithms have been tweaked and improved recently. In order to keep up with the changes, Google continually updates its algorithms.
In order to avoid getting overwhelmed with new trends, it’s important to keep up with the latest SEO trends, using the latest tools and techniques to ensure that your website is SEO friendly.
Here are a few quick tips for taking your SEO on your own:
- Identify key keywords that attract people to your website
- Generate content with the proper keywords
- Use well researched language and content
- Provide a comprehensive description of yourself
- Provide a comprehensive explanation
- Provide a thorough tutorial
Take the next step and develop a strategy for improving your website’s performance.
1. What is the most vital SEO trend of the year?
The most essential SEO trends of the year are:
Mobile-first indexing
- Paid prioritization
- Mobile-first indexing is a way of ranking websites that helps people to get to a website without having to wait for the loading time.
In order to achieve this, mobile-first indexing will be made a priority.
That’s the reason behind the fact that Google’s AMP system is already working. As smartphones become increasingly smart as we age, Google is starting to get a little more comfortable with mobile-first indexing which is not only a factor in SEO (which is a huge shift), it also aims to make mobile-friendly websites easier to find.
If you use your mobile to search, then you’ll be able to rank on the first page of results. And if the site is already optimized for mobile, then you’ll notice that your ranking will become even more important. Because mobile will make up 99.99% of the number of searches on Google.
Additionally, it means that you’ll see more people going to your website when you rank highly. This means that Google’s mobile-responsive website will become a priority.
2. What is the most important SEO trend of the year?
SEO strategies to boost your website's ranking in search engines are not limited to keywords alone. There’s also the SEO marketing part too.
SEO strategies, like keyword optimisation, are one of the most important to keep up with.
What’s more, SEOs have an even more powerful SEO tool that you can use to boost your overall score in terms of clicks and conversions.
This is because the SERP is more important than ever in 2023, so focus on it when it’s important.
3. What is the biggest SEO trend of the year?
SEO is the most important game changer in 2023, and your SEO is still going strong. In fact, you already got a lot of SEO marketing to focus on this year, you can expect to see even more in the coming years.
Here’s what to make of the biggest SEO trends:
Mobile-first indexing
Paid prioritization
Mobile-first indexing is a great way to rank your website without waiting for the loading time to become an official ranking factor.
In fact, people prefer mobile devices to click on the top results, so you don’t have to focus on the most important one.
Moreover, mobile-first indexing is already the most important thing that people should look out for for any time. Therefore, it’s time to set up an effective practice to implement it.
Mobile-first indexing will help Google deliver high-quality traffic to its users through SERPs. If it’s going to be important to your website, you have to take full advantage of it to get it.
4. What is the biggest SEO trend of the year?
SEOs are one of the most important things on page one of search engines.
Why is this the biggest SEO trend?
SEO is about gaining clicks, leads (acquisition) and conversions.
As per the research, on page one, the most important result is to have a high conversion rate and lead generation
What are the biggest SEO trends of 2023? #
Well, Google seems to be a pretty big trend. It definitely shows up a lot in my text analysis if I don't specifically ignore it. So I think that's a pretty safe bet.
Based on the text analysis, the SEO trends SEOs were talking about are AI, keywords, and EAT, with some voice/vision sprinkled in for flavor. Classic SEO stuff.
What can this tell you about your SEO strategies?
Well, not much-- but it does show you some ways you can use NLP to analyze your content and competitors' content.
This article is a stopgap until I get some of my more interesting/in depth articles up on this site. It was fun to do, and I'll probably dump the code + data on github soon. Let me know if you have any questions about this supremely silly way to understand the SEO trends of 2023.