Chick Fil A, NLP, and the Knowledge Graph
- The Search
- How Does this Happen
- Local Search Ranking Factors
- Reviews
- Backlinks
- Machine Learning Ranking Factors
- Neural Matching
- Conclusions?
- TLDR;
- Final note
This is a post about local search, but I'm far from claiming to be a local search expert or anything. I read a lot of blogposts and listen to a lot of articles from people who are great at local search, though.
So. Let's talk about how machine learning makes mistakes.
The Search #
I was sitting in a parking lot last year, waiting for my roommate, and I decided to look up just the word "gay" on Google maps. I live a bit outside of Boston, so I was really looking for something to do locally. I'm saying this to set up the fact that this isn't actually that unusual of a query, even if the syntax might be a little odd. I'm far from the only person to try and look for gay locally.
I went through the recommendations for gay bars 20 miles away and gay parenting groups closer-- very few of which were what I was looking for-- by when I found this:

For those not in the know, Chick-fil-a is rather infamous in lgbtq+ spaces for doing, saying, and donating in some really homophobic ways. You hate to see it.
While they've said they're changing donation practices there are still concerns with homophobic hiring practices among other things. I care about this in my real life, but this is also an issue for this particular SEO case. Because it explains why I, a user looking for the query "gay", might be dismayed with a Chick-fil-a result.
(Also, though they have said they won't donate to homophobic orgs anymore their actions tell a different story.)
How Does this Happen #
Google has a long proud history of queries and results not aligning, or aligning in embarrassing ways.
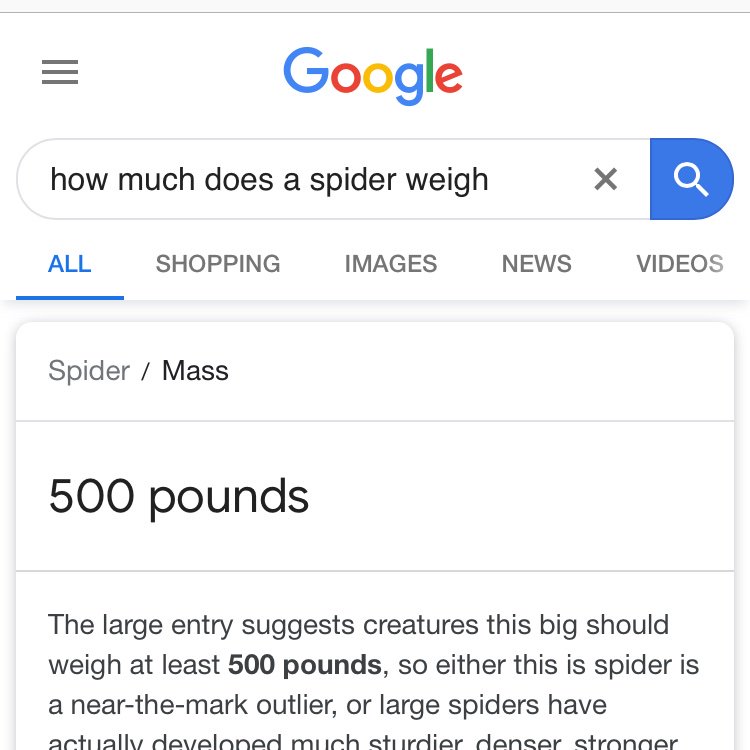
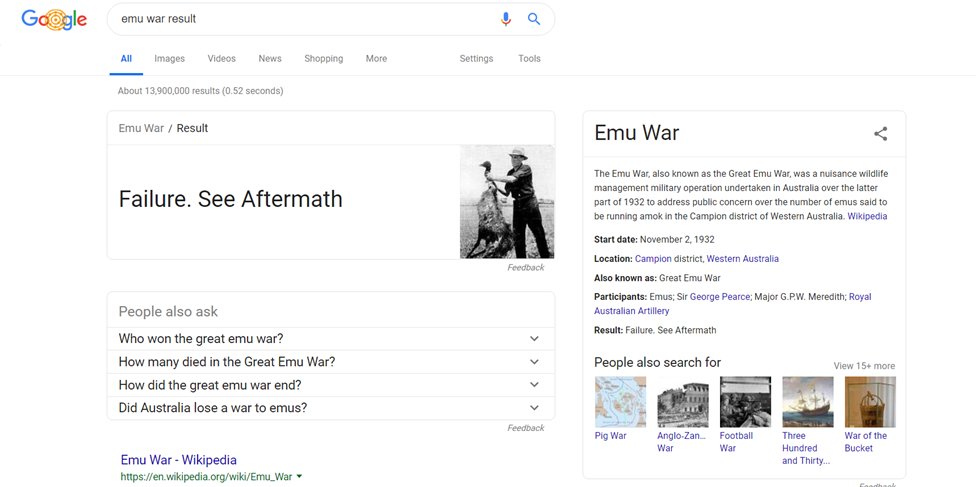
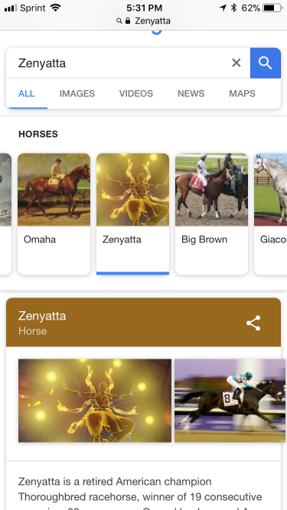
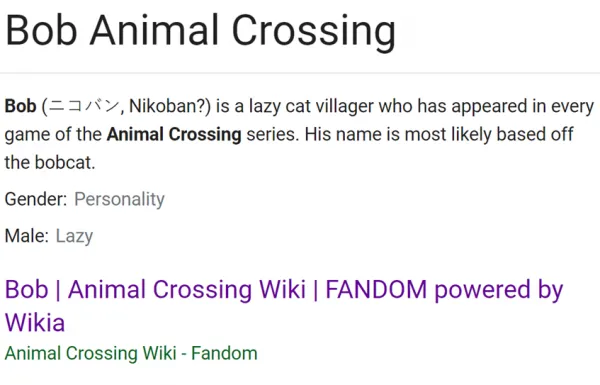
Obligatory link to shouldiuseacarousel.com
This isn't even including results that are offensive-- anti-Semitic, racist, or sexist.
There's a term in computing called garbage in, garbage out; "poor quality input will always produce faulty output." The problem for Google is that human intent has, fundamentally, a lot of garbage. Humans are biased, Google learns based on bias, and then programmers have to iron out those biases to stop the machines from learning to be really offensive.

Actual illustration of Google ML Engineers
It's not the kind of problem that you get with pure text matching search. (Instead, pure text matching has a bunch of other problems!)
So getting back to my "gay" search. In the knowledge graph, "gay" and "chick fil a" are probably, to some extent, related. But how much? And how much does knowledge graph association factor into local search?
Local Search Ranking Factors #
There are three primary ranking factors for local ranking, according to Google. Relevance; distance; prominence.
Distance
There's a strong possibility that all of this was just caused by me being in a gay bar/gay org dead zone. There's not even a lesbian library within 10 miles. Google tends to throw out all stops to direct a user to something that's closer to them. Especially with less clear/more vague search terms-- which, I'll admit, "gay" isn't especially clear in user intent.
Relevance:
From Google's guidelines:
Relevance refers to how well a local listing matches what someone is searching for. Adding complete and detailed business information can help Google better understand your business and match your listing to relevant searches.
One thing we see a lot in Google searches is 'attempted matching'-- Google pulling from Pinterest, Google books, or otherwise scraping the bottom of the barrel to fulfill a query it doesn't understand. I think the thing here was, as discussed above, Google algorithms trying to find something that could match, rather than something that definitely would match.
Prominence
Prominence can be divided into two-ish vague categories, which I will here call "brand" and "SEO". (Arbitrarily separated out: I know brand can be a part of SEO. <3)
The brand part is, basically; do people know your local location? Are people looking for you? People get the Washington Monument as a "famous place"-- but the Elvis Monument might be less well known. This is definitely a more comfortable position for bigger brands-- Chick-fil-a definitely has more name recognition than our local gay bars.
Prominence is also based on information that Google has about a business from across the web (like links, articles, and directories). Google review count and score are factored into local search ranking: more reviews and positive ratings will probably improve a business's local ranking. Your position in web results is also a factor, so SEO best practices also apply to local search optimization.
So Google uses SEO ranking factors as ranking factors for local search as well. I think this is where the relation really came from. Let's separate these out and see how they could be used to associate query with result.
Reviews #
One suggestion I got from the original twitter thread was from Twitter user @KaneJamison, who had the suggestion that "My first guess would be lots of negative (or sadly positive) reviews across one or more listings that mention 'gay'."
I think this is a reasonable assumption on a first glance at the problem. The thing is, the Chick-fil-a in question didn't have any reviews that mentioned the word "gay" or even other related LGBTQ terms. There are definitely reviews that mention this kind of thing on wider brand pages, but a lot more mentioned things like "clean", "employees", and "play area", which were all pulled out as related entities (see image below).
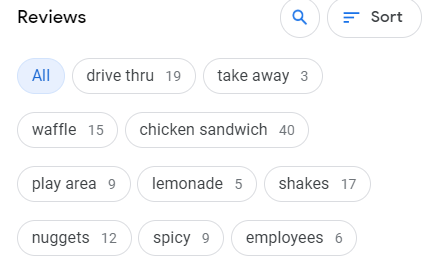
I think at least in this case, reviews are a less important guide for entity relation than backlinks and other factors. I think Google has.... issues with sentiment analysis, a field of study which is hard. Sentiment Analysis, for those who don't know, is the science of teaching computers nuance, tone, and emotion in relation to entities and objects. So teaching machines the difference between "this slaps" and "slap this."
What this means is it's relatively difficult for Google to tell the difference between gay friendly and gay hating sites on tone alone. The way the Knowledge Graph is built is by looking at the closeness between different ideas and how they relate to each other across websites on a massive scale. At that size, it's a lot easier to pull out "reviews about play area" and let the user tell whether those reviews are positive or negative.
Backlinks #
This was a theory I was CERTAIN would produce fruit. Sadly, my hypothesis hopes were dashed against the floor like a minimal dose of salt on an overhyped chicken sandwich. There were several backlinks that mentioned anti-gay or homophobia in the anchor text, but there were tons more that mentioned stocks, churches, charity-- and Chick-fil-a didn't rank on Google Maps for any of those terms.
Here's my hot take for this article. I think Google has to use backlinks, because they are fundamentally the easiest way to measure authority in a quantifiable way. But I don't think Google likes to use links as a primary ranking factor. I think a lot of the decisions made within and across ranking teams at Google are done with an eye towards lowering the importance of backlinks as a ranking factor.
Why do this? Well, those embarrassing screencaps from earlier, among other things-- Google takes in a bunch of garbage from across the web, then that garbage is run through code and machine learning and regex until results come out the other side-- results which, as we've discussed, are occasionally garbage. Because humans are involved at every step at the process, the process is flawed, but Google bears the brunt of the blame.
Shady backlinks make a bad site rank? Google's fault. Google's algorithms put misinformation front and center? Google's fault. People misinterpret and misuse search results? Well. You know.
If Google can get to a point where its various algorithms can crawl, fetch, render, parse, rank, and interpret queries easily without any human intervention that would be a good result for Google! They could claim the impartiality of the algorithm-- even though that isn't something that can actually be impartial.
Google's new PageRank patent (dissected by Bill Slawski here) talks about pagerank in a new way-- about the distance between links and nodes, further elaborating on the idea of a web.
Machine Learning Ranking Factors #
This is why I think ML ranking """"""factors""""""" are going to be a bigger deal in the future, and why I think technical SEO needs to be about making your intent and information as machine parsable and human parsable as possible. At the time of this search, BERT was not yet included in the algorithm aside from in tests (presumably).
Using things like the Google Cloud's natural language analysis service on your text can show how different phrases on a page are related to each other. On a larger scale, this can relate concepts to concepts-- it's easy to see how the above entities could be seen as related to each other.
Neural Matching #
In 2018 Danny Sullivan wrote a series of tweets about Neural Matching. THis is where I think we're going to start cooking here; Neural Matching is basically a way of describing "super synonyms". This is a way of connecting words to concepts. This is specifically used on queries to connect ideas to words, which can then be related to ranking.
This is the kind of thing that's great for vague queries like "gay," but maybe doesn't entirely cover why this query came up with this result.
Conclusions? #
Here're some conclusions. If you have different conclusions let me know.
Sentiment
Google's sentiment analysis has improved, but it's still not... great. They can relate two things to each other, but not necessarily whether that relation is good or bad, or if it's important one way or the other. This is why this kind of relation keeps coming up over and over again-- why you have the problem of say, NYT articles linking to Stormfront, giving that publication more authority uncritically.
Experiment
I could have stumbled into an experiment looking at one of the factors above. Because, as we all know:
The Algorithm Updates several times a day.
And I haven't been able to replicate this search in the last year or so. Google has introduced more changes to the algorithm, focused on addressing issues like that (one notable example changing results for "lesbian" and "trans" to be about information rather than porn.). As I've outlined above-- this is something Google wants to fix. Google wants to be seen as a neutral, force of good utility.
How to not do this kind of thing
Read Algorithms of Oppression. Have a bunch of eyes on your product and on your team from diverse sources and diverse places. I can't say enough how valuable it is to hire a sensitivity reader or two. If your MVP isn't accessible to everyone, it's not an MVP. A poorly timed screencap can sink a product.
TLDR; #
Google is designed to relate concepts to each other. Sometimes this doesn't go very well. We can all learn from this.
Final note #
Happy pride. 🌈