BlueSky vs. HuggingFace An Explainer for Normies
- The huggingface Bluesky dilemma: an explainer for normies
- What Happened?
- Why are people mad?
- What is HuggingFace?
- What is Scraping?
- Why Can’t Scraping Be Stopped?
- Can Bluesky Stop Scraping?
- Back to HuggingFace:
- What can be done?
- Conclusion… for now
The huggingface Bluesky dilemma: an explainer for normies #
It's Thanksgiving tomorrow so exactly the time for me to write a whole post about HuggingFace and the Bluesky situation. The drama. I’m probably going to break with many of the people mad at HuggingFace and many of the people at huggingface in writing this.
Also, I really recommend reading Dr. Casey Fiesler’s full thread on the situation!
What Happened? #
A developer associated with Hugging Face, an open source AI and ML platform, released a dataset containing one million public Bluesky posts. The dataset, intended for machine learning experimentation, made Bluesky users mad. They felt their content was being used for purposes they hadn't consented to, especially for generative AI training.
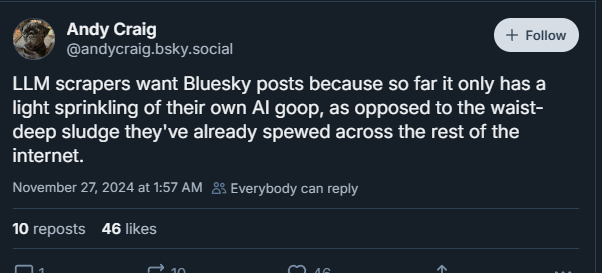
Why are people mad? #
Many people associate AI with generative tools like ChatGPT or Stable Diffusion, which can replicate or build upon human-created content. Creators and users often worry that their work is being used to train systems that could replace them or profit from their labor without compensation or consent. People feel their data is taken without their explicit permission. Although Bluesky posts are technically public, users expect some level of contextual privacy—they didn’t explicitly opt in for their data to be used in AI experiments. Users often don’t even know they’re in a dataset, making it difficult to request removal.
Content shared within a specific community can be amplified far beyond its original audience. The original intent of the post matters, as does whether it can be traced back to the user.
The internet has always kind of worked this way-- platforms like Twitter, Deviantart, Artstation get to display user posts alongside advertisements. In exchange, the user gets exposure, following, and opportunities. Generative AI comes from this deal but aims to-- intentionally or not-- replace the artist or writer.
In this way, Generative AI threatens jobs, and also feels like a violation of a user’s individual creativity. Once data is in a dataset, individuals lose control over how it’s used.
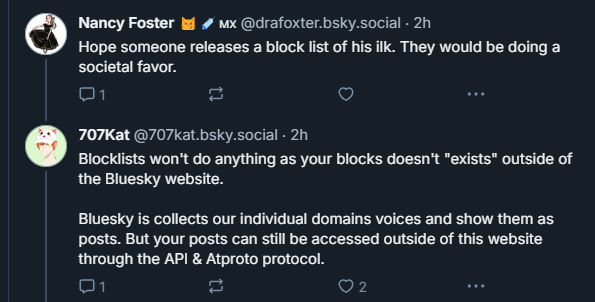
What is HuggingFace? #
Hugging Face, which hosts datasets for AI research, isn’t necessarily “the bad guy.” Their mission is to democratize AI, and they don’t create or approve every dataset hosted on their platform. However, this situation highlights a gap in ethical oversight for data collection.
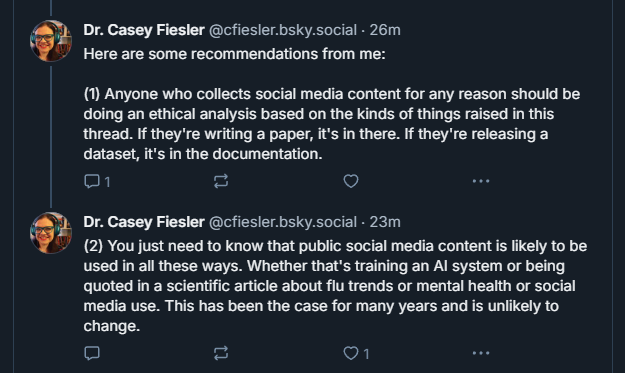
What is Scraping? #
Scraping refers to collecting large amounts of publicly available data, often using automated tools. It is a widespread practice across the internet. Google scrapes to make search results visible. Social media websites scrape web pages to make those little previews. While it can be used for ethically dubious purposes (like training AI models without user consent), it’s also a tool for legitimate use cases, like market research, accessibility projects, or academic studies.
But here’s the kicker: it’s almost impossible to stop. Even companies like Google, with enormous resources, struggle to prevent their search results and services from being scraped.
Why Can’t Scraping Be Stopped? #
If something is public online, it’s inherently accessible to anyone with an internet connection. Scraping just automates what you could manually copy and paste.
Even tools like CAPTCHAs, rate limits, or blocking IP addresses aren’t foolproof. Scrapers can mimic human behavior, rotate IPs, or use proxies to avoid detection. I have done all these things-- in my time being a human gremlin, I haven’t found a site that is impossible to scrape unless it was also really shitty for users. (This page might be close.)
Platforms like Bluesky are decentralized, which makes it even harder to enforce restrictions. A bad actor could scrape data from a user-hosted server instead of Bluesky's main servers.
Workarounds for Blocking: #
Platforms often provide APIs (like Bluesky's ATProto), which allow developers to access structured data legally. But these APIs are essentially pre-scraped datasets, and limiting their use is tricky.
Can Bluesky Stop Scraping? #
Not entirely. Bluesky operates as a decentralized platform with open protocols like ATProto, which makes it harder to prevent scraping. Even if Bluesky implements consent tools, these can only regulate what happens within their ecosystem—they cannot control third-party developers or researchers using external tools.
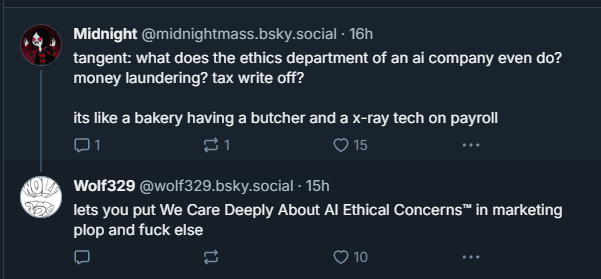
Legally, frameworks are limited. I think something people who don’t work in AI have trouble with is it is very hard to regulate LLMs and generative AI without regulating other parts of internet life. U.S. research ethics boards typically don’t oversee the use of public social media data because it’s not considered “human subjects research.” Scraping may violate a platform's TOS, but this doesn’t always equate to unethical use, and enforcement is inconsistent.
While users own their posts, copyright law is unclear when it comes to public social media data used for research or AI training. Fair use often applies to noncommercial uses but is less clear for commercial AI models. And HuggingFace is noncommercial.
Back to HuggingFace: #
After this happened, a lot of users learned about HuggingFace for the first time. And they were very mad-- because this was, it seemed, another AI company stealing their data. Unfortunately, I think people are shadowboxing at the wrong enemy here. . Unlike companies like Google or OpenAI, Hugging Face has built its reputation on transparency and openness. The goal is to share open source datasets, so people can see where their data is being used and how. They honor opt-out requests, letting people find their data and remove it from datasets. Compare with OpenAI possibly deleting evidence of their using NYT articles.
Companies like Google, OpenAI, or Meta often scrape quietly and train their AI behind closed doors. You won’t even know if your data was part of their models unless it’s explicitly leaked.
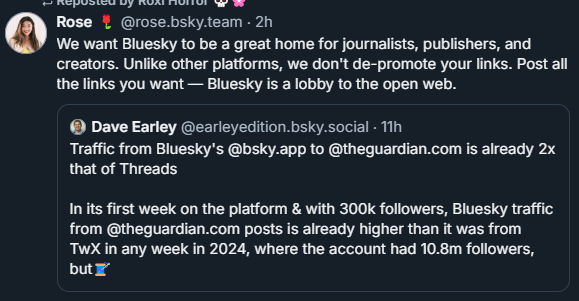
HuggingFace is maybe the only ethical ML company out there(™) right now. At least, the closest thing to it. The goals for the company are to democratize ML and ensure that companies like Google, OpenAi, and Meta have to comply by ethical standards-- and that large corporations don’t have total control over all machine learning. You may believe that Generative AI and machine learning are inherently evil things-- but they can only get worse when not held to account.
If you want to understand a way huggingface and scraping can be used: i have personally scraped a dataset of Yankee Candle reviews because I wanted to see if they really changed based on COVID spikes. This kind of research is also useful for seeing where right wing agitators are pulled towards or from, researching and detecting CSAM, and so on.
What can be done? #
Bluesky is considering tools like allowing users to specify consent for AI training. While this won’t stop all scrapers, it sets a standard for ethical use.
Companies can pursue legal action against blatant scrapers violating terms of service. However, this only works for centralized platforms and can be expensive.
Understand that public content is never truly private-- artists should include watermarks in their work. Writers should copyright your work and specifically not give permissions to scrapers for use in generative AI. Use Creative Commons licenses to set your terms for reuse.
You can even use unusual punctuation marks to fuck with crawlers - 。 for example. This can mess specifically with generative AI.
Conclusion… for now #
After backlash, the Hugging Face-hosted Bluesky dataset of 1M posts was taken down. While the removal was the right call in light of concerns, the incident has sparked important conversations about consent and transparency in data use.

Scraping itself isn’t inherently evil. Its ethicality depends on context: how data is used, whether users are informed, and if consent is respected.
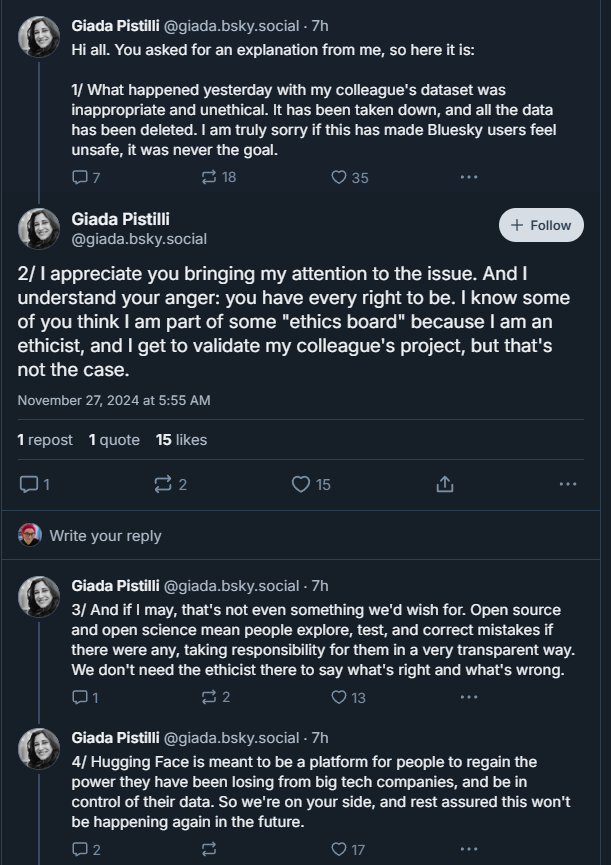
https://bsky.app/profile/enkikobunny.bsky.social/post/3lbvwx43ov22j
https://bsky.app/profile/andycraig.bsky.social/post/3lbvxxlx2fs25
https://bsky.app/profile/orpheusthelutist.bsky.social/post/3lbvigyjrss25
https://bsky.app/profile/danielvanstrien.bsky.social/post/3lbvih4luvk23
https://bsky.app/profile/cfiesler.bsky.social/post/3lbwurkbfcs2w
https://bsky.app/profile/clarkesworldmagazine.com/post/3lbwuqilk422o
https://bsky.app/profile/chickenpuppet.bsky.social/post/3lbvbzl4abc25