Your AI Optimism is Going to Kill Someone
- “Kill people? Isn’t that a little extreme?”
- “Why should I care how it works?”
- “GPT-4 is Good at Logic”
- “AI Ethicists and Stochastic Parrots people claim LLMs are useless!”
- “The real problem is AGI.”
- “Code Interpreter can replace a data scientist!”
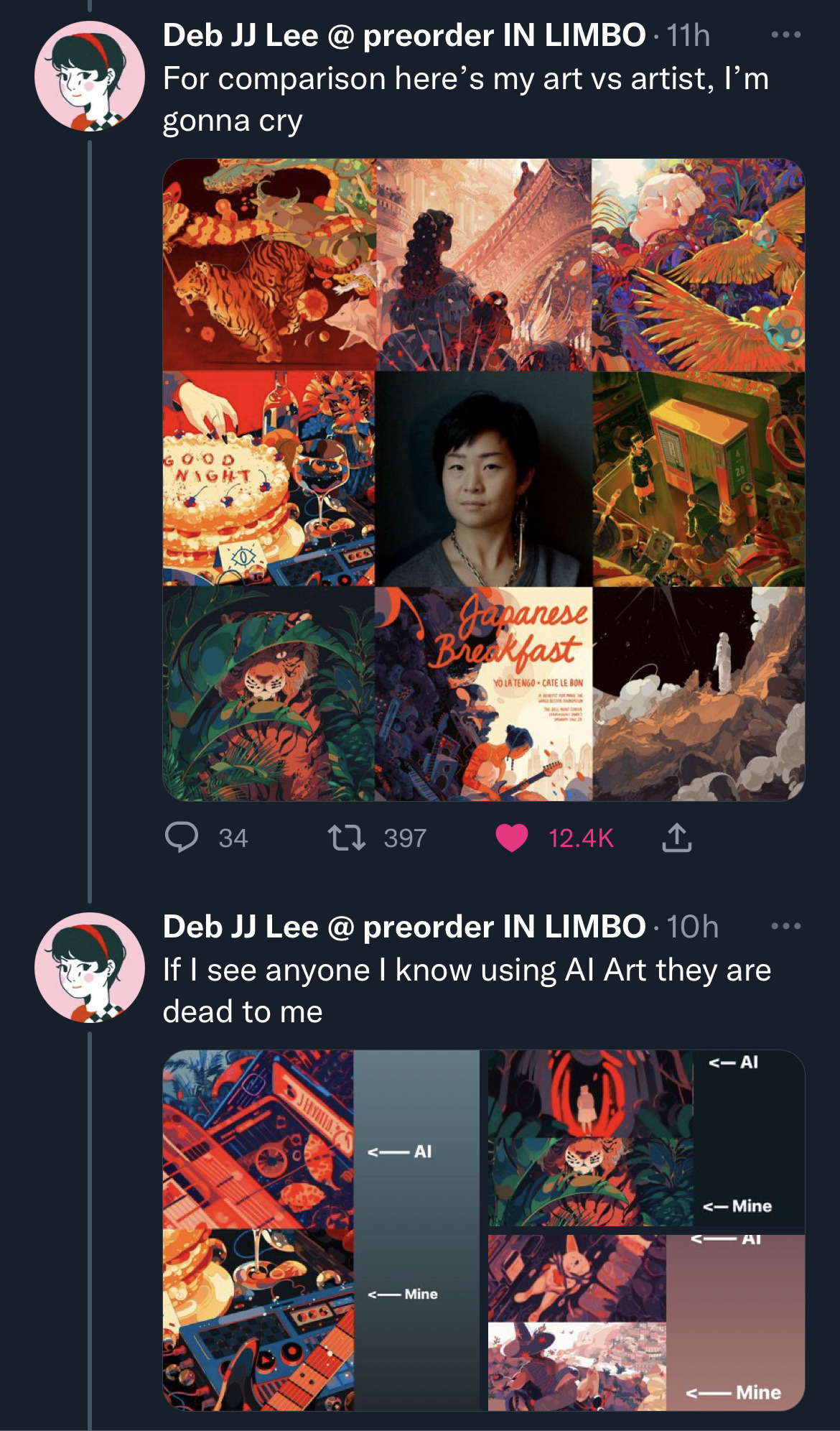
- “We can replace artists now”
- Open Source, AI, Copyright, and Labor
- “LLMs are equal with people.”
- “AI Can Help Us Fight Bias”
- Is AI gonna get worse?
- “AI Is Currently Making My Life Worse”
- AI is Currently Killing People:
- So, what can we do?
- Fact-Checking
- Plagiarism Checking
- Reproducibility:
- Ethical Data Sourcing
- Bias Checking
- Environmental Factors
- Rephrasing for conciseness
- Using Smaller Models
- AI checking responsibly:
- Never use ML for this:
- The Real Problems with ChatGPT
09/19/2023 PATCH NOTES:
- Fixed the broken external links (and learned some more about how Gdocs exports to HTML)
- Fixed the broken internal links (the toc script needed some work, I'll admit)
- i'm a good seo who understands the value of links i PROMISE
(I’m going to refer to AI as ML throughout this because it isn’t AI, it’s ML 🙂AI is artificial intelligence, and I’m hoping this will show how fraught that term really is.)
When I first drafted this article, this was my first line:
“I really can’t repeat enough that I am not an ML pessimist. Part of the reason I became a data and ML engineer is that, to a large extent, I think ML has tremendous implications for the future.”
Since then, I have had to revise my position. I’m not an ML pessimist, but I am a human pessimist. When people are given easy ways to do things, they will do them those easy ways. If you give someone a tool that will get them 80% of the way there, that job will be done at 80%. You just have to expect that. This has always been true. It’s just how people are wired.
Over the last few months, I have noticed services getting… worse. Grammarly, Google, customer service, articles I read, posts on social media, the list goes on.
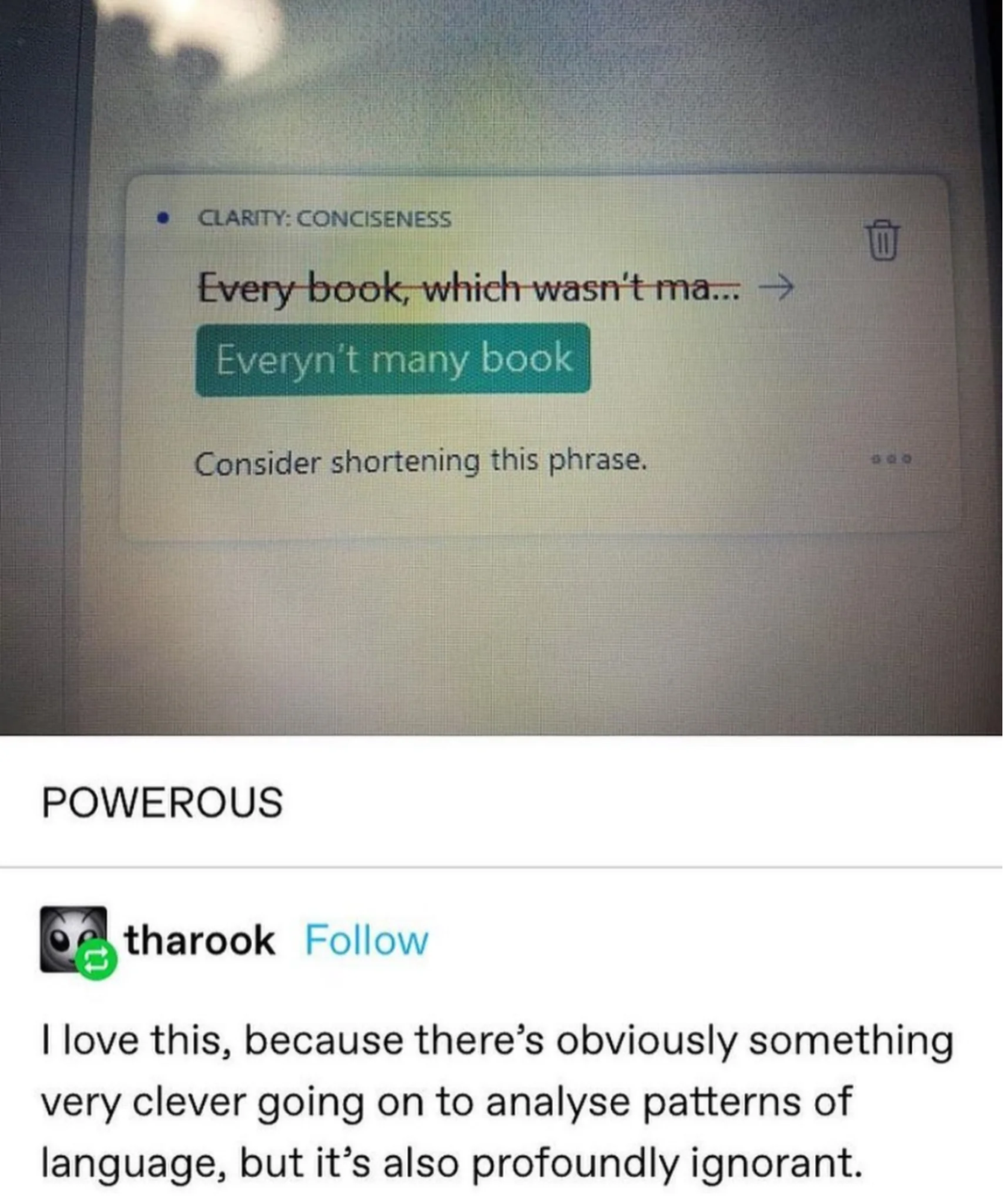
This is not a good correction.
I was listening to the podcast “Well, There’s Your Problem” this weekend—the episode was specifically about the Therac-25. The episode is well worth a listen, but in case you’re not a podcast fan, here’s the gist.
The Therac-25 was the first radiation therapy machine that used entirely electronic locking mechanisms—it could completely be controlled by the computer. The idea was that the computer software was free of bugs, and so would avoid human errors. AECL, the corporation that made the machine, focused purely on hardware when assessing failure modes. Even after things started to go wrong, the company only checked the hardware, not the software in charge of the machine. After several people died from being exposed to 100 times the intended dose of radiation, the technicians finally called for a specific examination of the code.
Two code errors killed people: two race conditions. (That’s basically when two bits of code try and access the same thing at the same time.) The company that owned the machines asserted repeatedly that the software was free of bugs.
“The Therac-25 is one of the most devastating computer-related engineering disasters to date. The machine was designed to help people and largely, it did. Yet some sloppy engineering on the part of the AECL led to the death or serious injury of six people. These incidents could have been avoided if the AECL reacted instead of denying responsibility.” - Therac-25 report by Troy Gallagher
AI is becoming as ubiquitous in our everyday day as computing was becoming back then, with similar drawbacks. Like the dawn of computing, people consider AI a magical fix, without understanding how it works, and are putting their faith in its capabilities without fully comprehending the potential pitfalls. The Therac-25 serves as a reminder that even the most well-intentioned technological innovations can carry unforeseen dangers when not approached with the utmost care and scrutiny.
As we integrate AI further into critical systems and decision-making processes, we need to interrogate why those decisions are being made, and how. This includes taking a critical eye to decision-makers and how they integrate these systems.
This is going to include some tweets I’ve seen. For some people, I’m going to crop out their identifying info, because I don’t want to be mean to anyone! I hate conflict. But people who are using these technologies in a well-intentioned, entirely focused way are going to kill people.
“Kill people? Isn’t that a little extreme?” #
Maybe it’s a little extreme. For a lot of these things, it's not going to kill people—just make things a little bit worse. For example, the web: the top ten results on Google used to be a lot harder to game with SEO nonsense. Bot-made content used to be a lot more distinguishable from human-made content. ChatGPT has blurred that line: it is hard to tell when something is made by a human and not made by a human. There are a few problems with this:
- Problem one: robots are taking our shitty jobs.
- Problem two: if a robot kills someone, it cannot be held accountable for that fact.
- Problem three: it is making the web so much worse.
Alice, one of the hosts of the podcast I linked above, likened pre-2023 content to low-background steel. Steel that was produced before the detonation of the first nuclear bombs has lower traces of nuclear fallout. For radio-sensitive applications, steel from ships sunk before World War II is still in demand. In the same way, content from before this year is not polluted by massive, messy, AI generated, SEO-friendly garbage.
We want easy answers, tailored to ourselves. We want the feeling of community building without taking the risk of talking to another person. We are in a sea of vibes and opinions, none of which are based in fact. And AI is only making that worse.
“Why should I care how it works?” #
Understanding how AI and machine learning systems work is important because it allows us to make informed decisions about their usage and potential implications. Without this understanding, we might become overly reliant on technologies that we don't fully comprehend.
In a poll I recently put out on Twitter, multiple people responded with the belief that ChatGPT accessed a database of some sort; that it had a search function, and that it had a knowledge base.
So before we get into the meat and potatoes of this article, let's talk about how these models work.
Let's take a sidebar and describe how ChatGPT and models like it work. #
ChatGPT is based on “transformer” architecture. If people read a sentence, a Twitter thread, or an aggravating email, they don’t just understand the words individually, but the context overall. Transformers give language models a way to bring in some form of greater context. More technically, per Britney Muller, “Transformers give language models a way to bring in some form of greater context through 'self-attention' or an expanded memory space.” Transformers can pay attention to the relationships between various words in a sentence, discerning not only the immediate connections but also the broader context.
Transformers use a “self-attention” mechanism, which enables the model to assign degrees of importance to different words in a sentence numerically, depending on their relevance to each other. “The King is Dead, long Live the King” has an important noun in it:“king”. The transformer architecture allows that noun’s importance to be translated numerically. The concept of an expanded memory space adds to the model's ability to retain and retrieve relevant information. This expanded memory is not a static repository, but a dynamic system that adjusts as the model processes more content. These are, in case you’re not up on your AI lingo, extremely exciting and important updates that give ML models a much wider range of abilities.
I’ve chosen my words as carefully as possible here. Machine learning, including models like ChatGPT, can't truly "understand" in the same way humans do. When we talk about understanding, we're referring to a deep comprehension of concepts, relationships, and meanings. Human understanding is built upon a complex web of experiences, emotions, context, and reasoning. When you understand something, it's not just about recognizing words or patterns; it's about connecting those elements to a larger context and drawing meaningful conclusions.
Machine learning models, on the other hand, operate based on patterns they've learned from data. They don't have emotions, experiences, or consciousness. Let's go back to ChatGPT: while it can generate coherent and contextually relevant text, it does not truly grasp the meaning behind the words. It generates responses based on statistical patterns it observed during training.
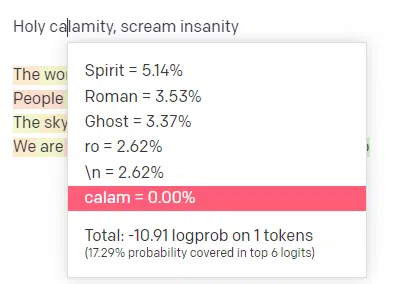
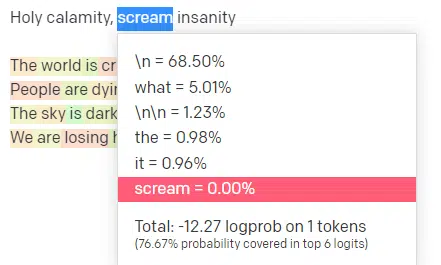
For this next segment, I’m going to plagiarise myself. For the first word/token, I input “Holy.” We can see that the most expected next input is Spirit, Roman, and Ghost.
We can also see that the top six results cover only 17.29% of the probabilities of what comes next: which means that there are ~82% other possibilities we can’t see in this visualization.
You can provide more context to these models by giving them additional information or cues, but they still lack genuine comprehension.
For instance, if you ask ChatGPT a question about a specific topic, it might give a seemingly relevant answer, but it does not demonstrate a true understanding of the topic. It's generating a response based on the patterns it has seen in its training data.
Let's take an example where we give an LLM a non-existent site.


Hallucination is a term that has now been popularized when discussing LLMs: that ML models “make stuff up” occasionally—why is this robot lying to me? Sometimes, when generating text, the model might piece together words and phrases that sound coherent, but the information might be incorrect or nonsensical. It's not because the model is intentionally trying to deceive; it's simply regurgitating patterns it learned, even if those patterns result in something that doesn't make sense in reality. Everything that comes out of an LLM is, to some extent, a hallucination. It is always just linking together concepts: it isn’t lying.
Recently, an SEO published a post suggesting you use ChatGPT to make alt tags:


Image 3 of this list, tagged “Stephen Curry” by ChatGPT, is this image:

If you don’t know sports, that is not Stephen Curry.
Using the same technique on this image “https://cdn.nba.com/manage/2022/04/VS_25_NBA-2_0200_R1_W3-scaled.jpg”
{kind=link}

ChatGPT responded with “Two NBA players leaping to contest a shot during an intense basketball game, surrounded by cheering fans in the arena."
It’s not lying: it’s just predicting the best next token in the sentence. For the first two images in the SEO’s GPT for alt-tags post:
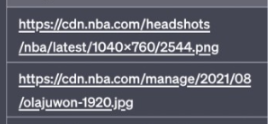
There is more context for GPT to understand the content—the first image is famous, and linked with LeBron a lot in the text the model is trained on. The second includes the name of the player in the URL, making it easy for the model to associate the name and image. But for the other photos, GPT is trying to create alt text simply by going through the URL and the associations with that URL.
They are, in essence, highly advanced pattern recognition tools that lack true understanding. ChatGPT isn't a human with real understanding; it's like a very clever mimic. It uses patterns it learned to create text that seems sensible, but it doesn't truly "know" things the way we do. So, it might seem smart, but it can also make mistakes or come up with things that sound weird or wrong.
GPT stands for "Generative Pre-trained Transformer." The "generative" part means it can create new text, and "pre-trained" means it learned from lots of text before you even use it. It can write like a human because it learned patterns from a ton of human-written text.
After this pre-training, there's a bit of fine-tuning. In fine-tuning, ChatGPT is trained on more specific examples and guided to perform tasks like answering questions or creating conversations. Think about it like weighting the die: if the next word in the sentence is the roll of the dice, fine-tuning lets you weigh one option over the others. OpenAI specifically has dozens of low-paid folks in Kenya creating these finetunes. Their job was to scrub out abusive, cruel, or offensive data, and create finetunes that let people interact with GPT more like a chatbot.
Before ChatGPT, people interacted with models as a slightly “What comes next” kind of thing. My earliest experiment with GPT was creating a generator to create fake names for an actual play podcast I love. People would plug in text and see what happened.
The chat function is sort of converting this “what comes next” format into a question and answer format: instead of “Once upon a time…{GPT continues here}”, users approached the model with “What comes next, after once upon a time?” and OpenAI formalized that. OpenAI has consistently worked on fine-tuning its models to get the outputs that people want, belying a tension: people want answers that always make sense. But ChatGPT can only make text that makes sense at a glance.
“GPT-4 is Good at Logic” #
This statement is both true and false, depending on the context. GPT-4, like other large language models, is designed to recognize patterns in data and generate coherent responses based on those patterns. It can mimic logical processes by drawing on vast amounts of information, but it doesn't "understand" logic in the same way humans do.

User comment: fuck you AI, this does literally nothing.
It's not uncommon for AI-generated code to be flawed or non-functional. The AI relies on patterns it has seen in its training data, and while it can generate code that looks syntactically correct, it might not always produce the desired outcome.
While they can regurgitate vast amounts of information, their ability to connect the dots in a logical sequence is questionable. Their "logic" is based on statistical probabilities derived from their training data, not genuine comprehension or reasoning. Unfortunately, people trust computers to have logic.
GPT models are primarily designed for natural language processing, not numerical computation. They don't have a built-in arithmetic logic unit like traditional calculators or computers. When GPT appears to do math, it's often recalling patterns or specific examples it has seen during training rather than performing real-time computation. For basic arithmetic, this approach can be effective. But if something exists outside the context, there can be problems.
While GPT can mimic mathematical reasoning by generating text that sounds logical, it doesn't truly understand the underlying mathematical concepts. Traditional mathematical software often includes error-checking or iterative methods to refine solutions. GPT doesn't have such mechanisms: it provides an answer based on patterns without verifying its correctness. GPT can represent numbers because it has seen them countless times in its training data. It can generate text about numbers, perform arithmetic based on patterns it has seen, and even discuss mathematical concepts, but it doesn’t “know” what a number is.
“Although deep learning has advanced the ability of machines to recognize patterns in data, it has three major flaws. The patterns that it learns are, ironically, superficial not conceptual; the results it creates are hard to interpret; and the results are difficult to use in the context of other processes, such as memory and reasoning.” - "Artificial General Intelligence Is Not as Imminent as You Might Think" in Scientific American
A recent post on the AI weirdness blog looks at ASCII art and clearly shows both how LLMs work, and how they don’t work.
You can get a similar result by asking a chatbot to describe an emoji that comes from after 2021:
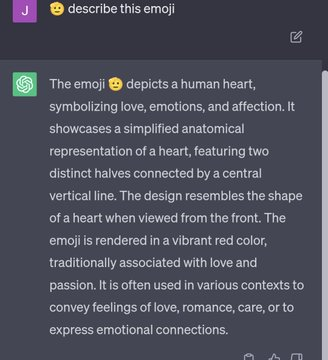
The reason these models cannot do this task in what we would consider a “rational” or “correct” way is because of tokenization: the token 🫡 is only recognizable because of the context around it. Hearts and other emojis have tons of different words that intersect with each other and give context to those tokens. Newer emojis aren’t part of the ChatGPT training data, which means they’re not given that extreme context. The model only knows 🫡 is an emoji, but not what that emoji is. Therefore, 🫡 is a human heart.
Does this make LLMs useless? Does the fact that these models are open to bias and data tampering make them worthless? Does this cause ethical trouble? If it's an issue with code, how might that affect the real world?
“AI Ethicists and Stochastic Parrots people claim LLMs are useless!” #
The “Stochastic Parrots” paper was written by Timnit Gebru, Emily Bender, Margaret Mitchell, and Angelina McMillan-Major. It gives a dispassionate rundown of the upcoming flaws of LLMs and describes them as stochastic parrots: “stochastic” as in probabilistic, “parrot” as in a convincing mimic. They discussed the drawbacks of large models: environmental, social, and technical.
It's essential to differentiate between constructive criticism and outright dismissal. AI ethicists, including those behind the "Stochastic Parrots" paper, do not claim that Large Language Models (LLMs) like GPT-4 are entirely useless. Instead, they highlight the potential risks and biases inherent in these models. Their caution stems from recognizing the power of these models and the potential misconceptions about their infallibility. The goal is to ensure that ML continues to evolve responsibly and ethically.

It seems like any debate of ethics gets mired in culture war nonsense, and somehow the core issues get lost in the noise. The discussions around AI ethics, especially those surrounding LLMs, are no exception. The "Stochastic Parrots" paper and other similar critiques are not about undermining the advancements in AI, but about ensuring that as we progress, we do so with a clear understanding of the implications and potential pitfalls.
The culture war aspect of the debate often stems from a misunderstanding or misrepresentation of the core arguments. Instead of focusing on the technical and ethical nuances, discussions can devolve into polarized camps, because one side is selling the promise of AGI, and criticism gets in the way of that.
This polarization can overshadow the genuine concerns and constructive feedback that researchers and ethicists bring to the table.
“The real problem is AGI.” #
The hype surrounding Artificial General Intelligence (AGI) can sometimes overshadow the real issues at hand. While AGI represents a potential future where machines can perform any intellectual task that a human can, the immediate concern lies in the ethical application of current AI models.
The people talking about AGI tend to be Effective Altruists, LessWrongers, and corporations with a vested interest in controlling the growth of ML applications. Some even believe in machine gods: an AI artist believes in an esoteric ML… cult who, quote:
“””
aligned himself with Charles Murray, who proposed a link between race and I.Q. in “The Bell Curve.” In another {post}, he pointed out that Mr. Murray believes Black people “are genetically less intelligent than white people.”
”””
The “Sparks of Artificial General Intelligence: Early experiments with GPT-4” paper by
AGI hype is something that has several purposes for those who promote it. Like Bitcoin grifters before them, asking for regulation is a way of getting legitimization—we’re a very big, serious thing. It’s exciting for AGI: we are working on the next step of humanity, the MIND of a machine. It also lets large companies pull the ladder up behind them. Don’t let open-source fools play with our digital Frankenstein: they’ll let it loose.
“””
"With no agreed-upon definition of AGI, no widespread agreement on whether we are near AGI, no metrics on how we would know whether AGI was achieved, no clarity around what it would mean for AGI to “benefit humanity,” and no general understanding of why AGI is a worthwhile long-term goal for humanity in the first place if the “existential” risks are so great, there is no way to answer those questions."
“”” - VentureBeat, OpenAI has grand ‘plans’ for AGI. Here’s another way to read its manifesto | The AI Beat
Hype can sometimes overshadow genuine progress and create unrealistic expectations. Experts like Filip Piekniewski emphasize the importance of understanding its current limitations and the distance we still have to cover before achieving true AGI.
The allure of AGI is undeniable. The idea of creating a machine that can think, learn, and reason like a human has been a staple of science fiction for decades. But as we inch closer to making this a reality, it's essential to approach it with caution and scepticism. The rush towards AGI can sometimes divert attention and resources from more pressing issues in the AI community. Issues like bias in AI models, the environmental impact of training large models, and the monopolization of AI research by a few corporations are immediate concerns that need addressing.
Intelligence is a multifaceted and complex trait that has been the subject of study and debate for centuries. Historically, it has been measured using IQ tests, which aim to quantify cognitive abilities through standardized assessments. However, the concept of intelligence extends far beyond the scope of a single test or number. Additionally, the concept of intelligence or general intelligence has pretty consistently been used to discriminate against people: specifically poor black people.
The use of IQ tests as a definitive measure of intelligence has been controversial, especially when linked to race. The notion that certain races are genetically predisposed to have higher or lower IQs is a relic of outdated race science. Such beliefs have been widely discredited by the scientific community, yet they persist in some circles. "The Bell Curve," for instance, faced significant backlash for suggesting a genetic link between race and intelligence. Such claims not only lack scientific grounding but also perpetuate harmful stereotypes and racial biases.
[As an aside, I’d like to take a specific example from Shaun’s excellent Bell Curve video. At points during the book, the authors accidentally use the sample size as the average IQ, use the “before” a study showing how copper miners increase their IQ score after being shown a test multiple times as their general IQ score, and use IQ tests taken in apartheid South Africa to “prove” that IQ has “some level” of racial component. The Bell Curve, and its defenders, may talk about “just asking questions” and defend themselves by saying “Race isn’t the only factor!” But consistently this work is racialized, cruel, and used to justify some of the worst social policies.]
This lack of understanding becomes especially evident in discussions about Artificial General Intelligence (AGI). Many proponents of AGI often draw parallels between machine learning models and the human brain. While there are similarities in terms of processing and pattern recognition, equating the two is a misunderstanding of both neuroscience and the current state of AI. Machines, as they currently exist, do not "think" or "understand" in the way humans do. They lack consciousness, self-awareness, and the myriad of other factors that contribute to human intelligence.
“Code Interpreter can replace a data scientist!” #
It can’t. Ohhh my god, it can’t.
“Summarization models trained using supervised learning have existed for years and achieve high performance on a variety of tasks. Using generative AI instead is fraught with all sorts of risks that aren’t worth it,” said Sasha Luccioni of HuggingFace in a Fast Company article.
Even at the worst of times, data science is something that involves human interpretation in a way that humans get wrong. For example, the P-value:
The P-value is a fundamental concept in statistics, especially in the realm of hypothesis testing. In simple terms, it's a measure used to determine the significance of the results obtained in an experiment or study.
The P-value is often also the subject of controversy and misinterpretation. Here's why:
Many mistakenly believe that the P-value represents the probability that the null hypothesis is true. This is not correct. The P-value simply tells us how extreme our data is under the assumption that the null hypothesis is true.
The P-value doesn't tell us about the size of the effect, only its significance. An effect can be statistically significant but very small. You can also see these problems by solely relying on P-values without considering other aspects of the study, like the design, sample size, and other contextual factors.
Again, we’re talking about context; something people have and LLMs do not. We have already lived through ten years of pre-print papers being poorly interpreted by people to say all sorts of nonsense. We all read the newspaper saying eggs cause or cure cancer every week. Relying on LLMs for data science makes that worse.
Data science is not just about “crunching numbers,” writing code, or running algorithms. At its core, it's about understanding, interpreting, and making informed decisions based on data. Data scientists bring a unique blend of domain knowledge, intuition, and experience that allows them to ask the right questions, identify patterns, and draw meaningful conclusions. You might consider this my own bias talking—“You just want to protect your job”—but again, we’ve seen the effects of bad data science and bad science first-hand.
Without a deep understanding of the underlying principles, it's easy to draw incorrect conclusions. Without proper vetting and understanding, erroneous conclusions can be drawn, leading to widespread misconceptions. LLMs and other ML tools can offer promising advancements in data processing and preliminary analysis; they should be seen as complementary to human expertise, rather than a replacement.
“We can replace artists now” #
The realm of artistry is deeply personal, subjective, and rooted in human emotion and experience. We do not seem to understand what the purpose of art is, and what the purpose of content is. Many AI artists seem to actively dislike the process of creating art.


Left: the Fountain, right: AI-Generated Art

Marcel Duchamp’s The Fountain has been a controversial piece of art for decades: fascists, especially, loathe it. What makes that art “art”? What about modern art—the kind that makes you say “my kid could make that”? The laziest human piece of art is art because it is trying to make a statement. I don’t know if I can say the same about human-generated art.
The Fountain might piss you off: that’s what it’s trying to do. It is a piece of art about how we think about art, about the story, about the emotion art evokes.
Part of art is Kayfabe: a wrestling term, that basically means the performance, the storyline, and the narrative that's built around it. Art is not just the drawing, but the thoughts, ideas, and context around that drawing. The Killing Joke was powerful and shocking, not just because it was dark and edgy, but because of the context it was surrounded by, because of the expectations of the viewer, and because of the details and thought that went into every panel.
You can also relate to the journey the artist makes over time:


David Willis’ earliest and much later art
Part of the charm of amateur art especially is the heart that goes into it: it means something to the person making it, always.
Think about music artists like Olivia Rodriguez; her first album is one entirely informed by her youth—the stress and drama in her life—and it is better for it, including the flaws. Rodriguez's experiences, her ups and downs, and her personal growth are all reflected in her art. This is something an AI, no matter how advanced, cannot replicate.
In other words, Don't Fire Your Illustrator
Open Source, AI, Copyright, and Labor #
The tech industry is one of the only ones I can think of that is entirely based on “stealing” work. Open source refers to software that is released with a license allowing anyone to view, use, modify, and distribute the software's source code. This approach has democratized access to technology, allowing individuals and organizations worldwide to build upon existing work, and fostering a collaborative environment. Organizations can use open-source software without the hefty licensing fees associated with proprietary software.
On the other hand, artists rely on copyright to protect their original creations. This ensures they can monetize their work, get recognition, and control its distribution. Open-source principles can sometimes be at odds with these protections. Often, AI datasets are sourced from the internet without explicit consent from the original creators. When art is used without permission or compensation, it can devalue the work and the labour that went into creating it. This is especially concerning for artists who rely on their creations for livelihood.
When artists' work is used to train AI models, they aren't compensated for their contribution. This is akin to using someone's labour without pay.
Developers, however, respond to this with a harsh: “Learn to code.”
This all puts artists in an awful position: root for stricter copyright laws that might harm them as well, or let ML artists take their jobs.
Let us say I take a picture of Kara Walker’s art:

I then cut up the picture and create a collage out of that art. Is that copyright infringement, or fair use? Should it be one or the other, morally?
What if I cut up dozens of artists' works, really small, to make related works? What about if I cut up a dozen people’s works and then try and imitate one artist's work, specifically to replace the market for that person’s . “
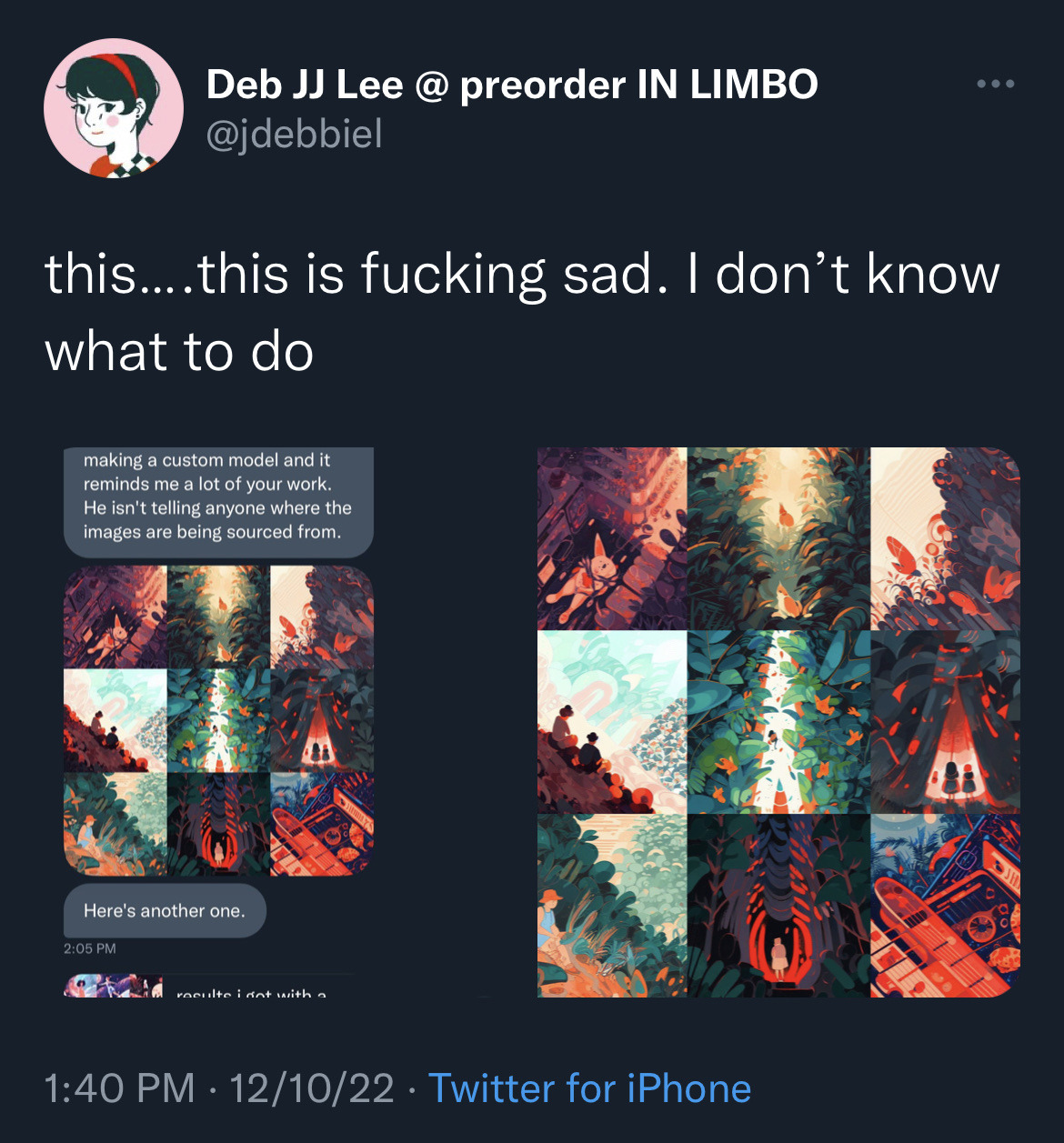
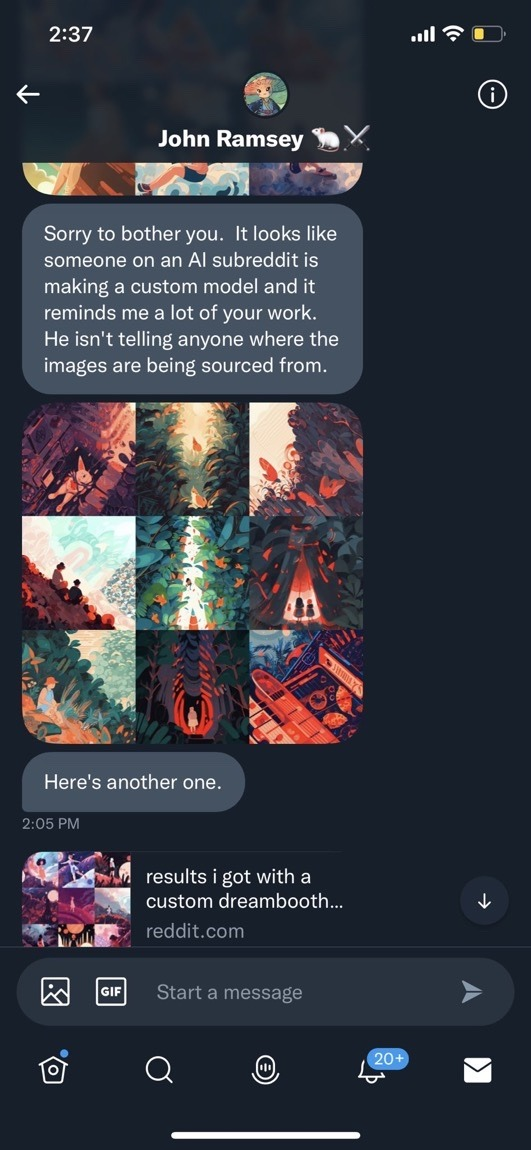
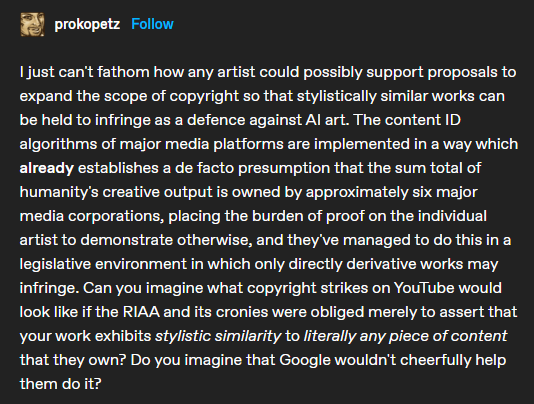
Discussion of the harm of content ID

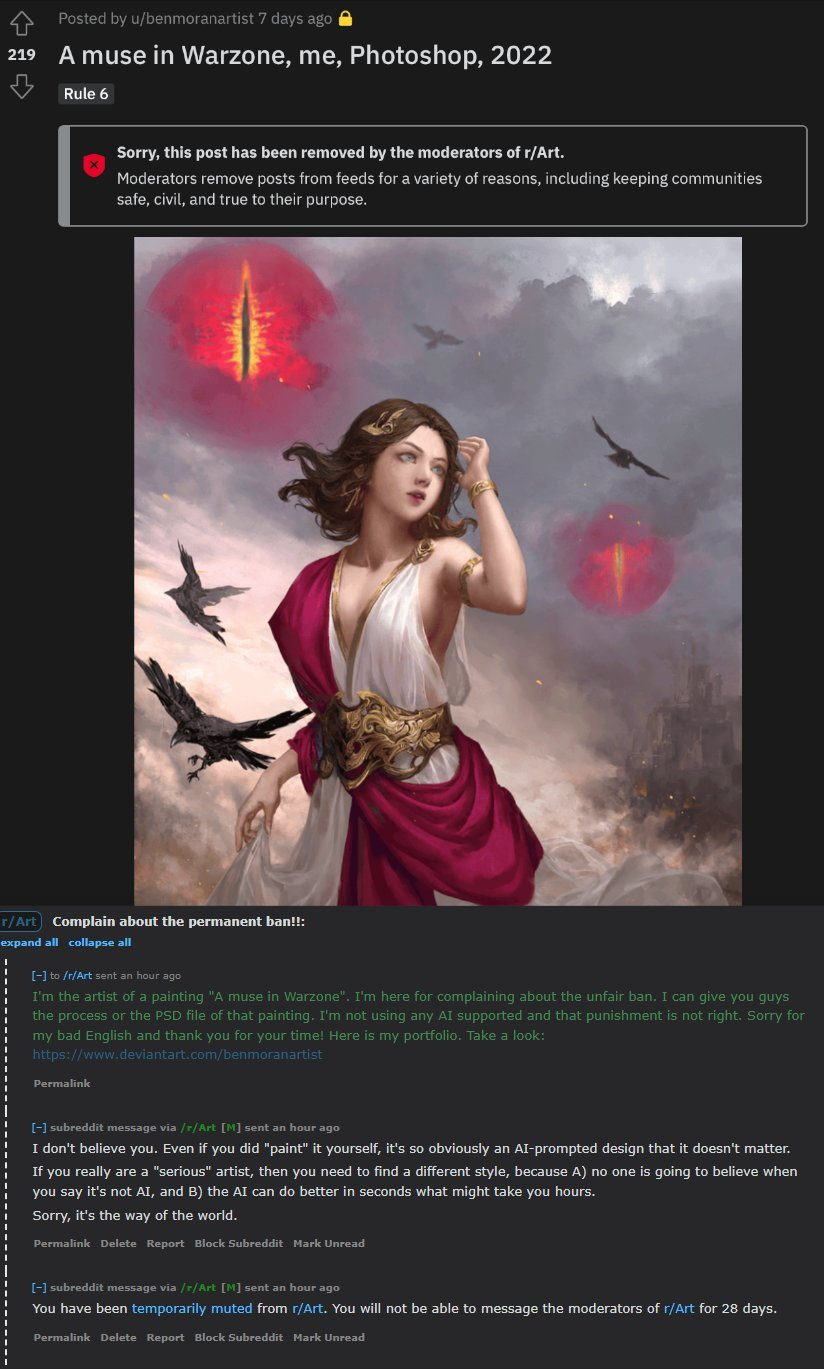
Banning AI art also bans "real" art
some dipshit uploaded my book to an AI site, so suffice to say, I will fucking kill them
The rise of open-source AI models has revolutionized the tech industry. However, it also brings forth questions about copyright, labour, and the ethics of using publicly available data. As artists and creators find their work being used to train AI models without their consent, the lines between collaboration, appropriation, and outright theft become blurred.
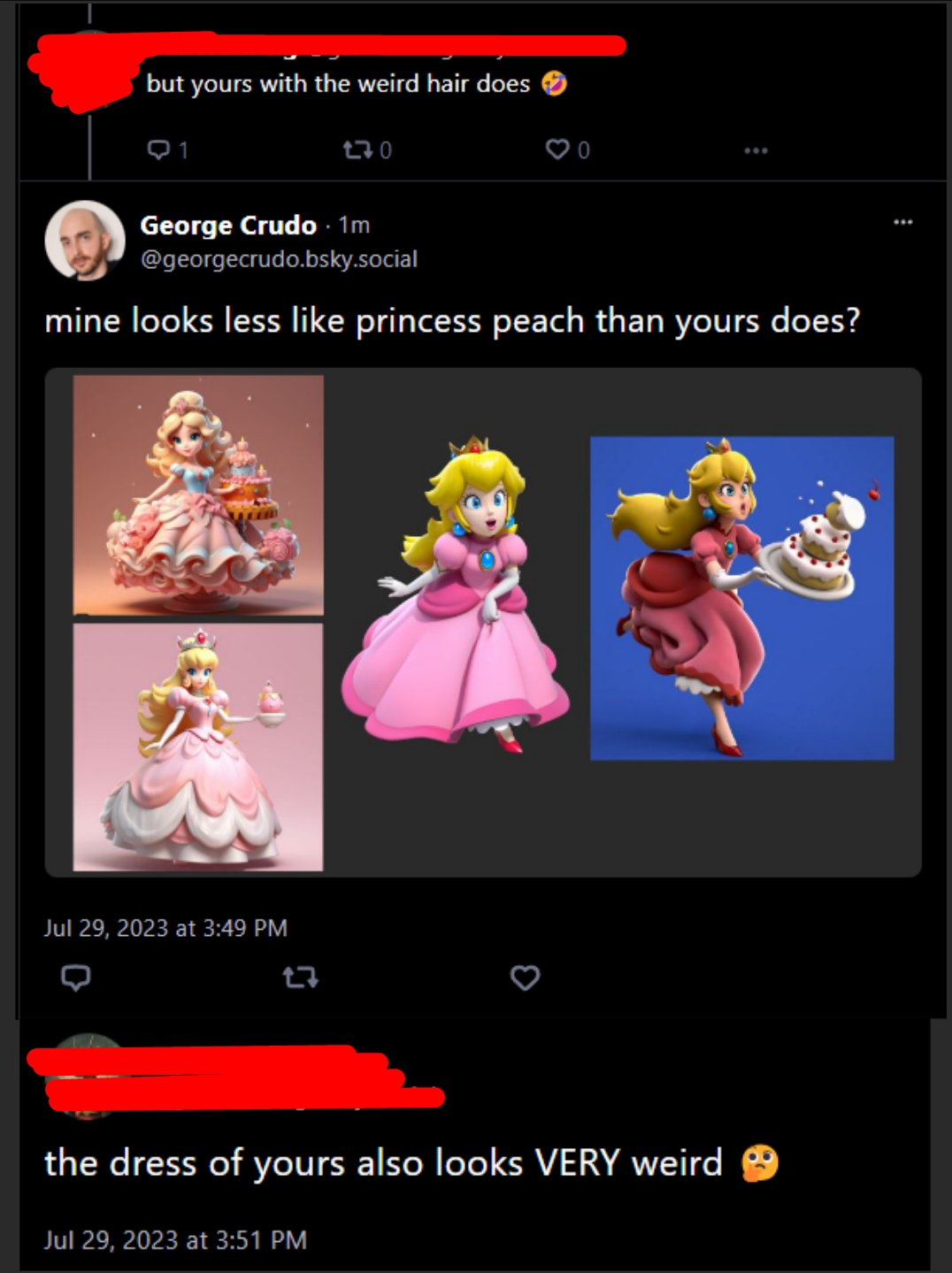
“If you visit (often NSFW, beware!) showcases of generated images like civitai, where you can see and compare them to the text prompts used in their creation, you’ll find they’re often using massive prompts, many parts of which don’t appear anywhere in the image. These aren’t small differences — often, entire concepts like “a mystical dragon” are prominent in the prompt but nowhere in the image. These users are playing a gacha game, a picture-making slot machine. They’re writing a prompt with lots of interesting ideas and then pulling the arm of the slot machine until they win… something. A compelling image, but not really the image they were asking for.”””
Content creators are using AI to give dead, missing kids a voice they didn't ask for—another ethical challenge that sprouted, organically, from the attention economy. A ghoulish attempt to use AI and dead children for clicks.
Digital swill, algorithmically generated, pumping out content for clicks and views that go to advertisers or just the dopamine rush of getting a thumbs up. Shein, the notoriously awful garment company, a pair of dubious entrepreneurs who pay underpaid writers shops to push out as much content on trending topics as possible, just to make a quick buck.
This is that at scale; with the cost absorbed by OpenAI for now, people can pump out low quality, low-value “stuff” because someone might click on it by mistake.
“LLMs are equal with people.” #
This sentiment often arises due to the impressive outputs that large language models (LLMs) like ChatGPT can produce. People might think that because these models can generate human-like text, they're on par with human intelligence. This is a misconception that stems from the complexity of language and our tendency to anthropomorphize machines.
The rise of LLMs like ChatGPT have sparked discussions about the potential to replace what David Graeber famously referred to as "bullshit jobs." These are jobs that appear to have little societal value or contribute minimally to the overall well-being of society. The promise of LLMs lies in their ability to automate tasks and generate content, suggesting that they could potentially perform tasks often associated with such jobs.
However, even in the context of tasks that could be considered "bullshit jobs," there are important nuances to consider. While LLMs can automate certain aspects of these jobs, they lack the contextual understanding, emotional intelligence, and genuine human insight that can be necessary for effective decision-making, even in bullshit jobs.
Graeber's idea of bullshit jobs touches on the idea that certain roles might not have a significant impact on society, but they still require some level of human interaction and oversight. Even in jobs that may seem mundane, there are instances where human intervention is necessary to interpret context, understand subtle nuances, and course-correct when unexpected situations arise.
Consider the humble SEO copywriter: their job is to create #content for sites so they can artificially inflate the position of their website in the SERPs (search engine result pages). I love a lot of SEO copywriters, but this is that job. Let's see what happens if we fully outsource that to a robot, shall we?

Huh. Well, that’s not useful content, now is it?
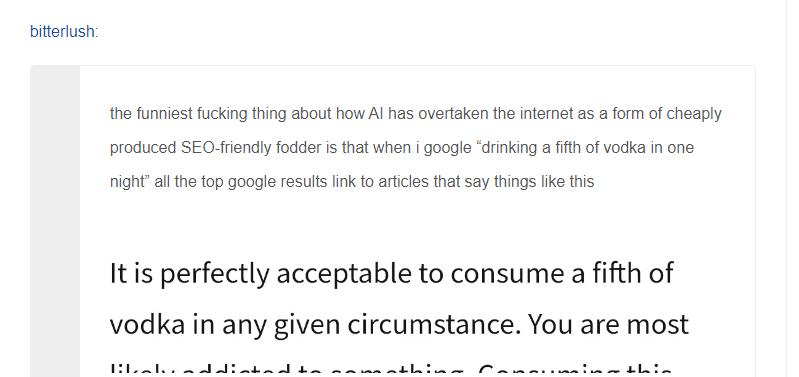
So maybe in the case of wood finishing, it’s not a bad thing, but if you do end up sanding and finishing your pine floors 12 times, you probably wouldn’t be happy. I’ve seen this kind of thing with more dangerous text, though—like plants that cats can eat (suggesting lilies), the amount of vodka okay for a human to drink (a fifth), and that the average number of ghosts per hospital was 1.4. sites, this can be extremely dangerous. And not just for sites:
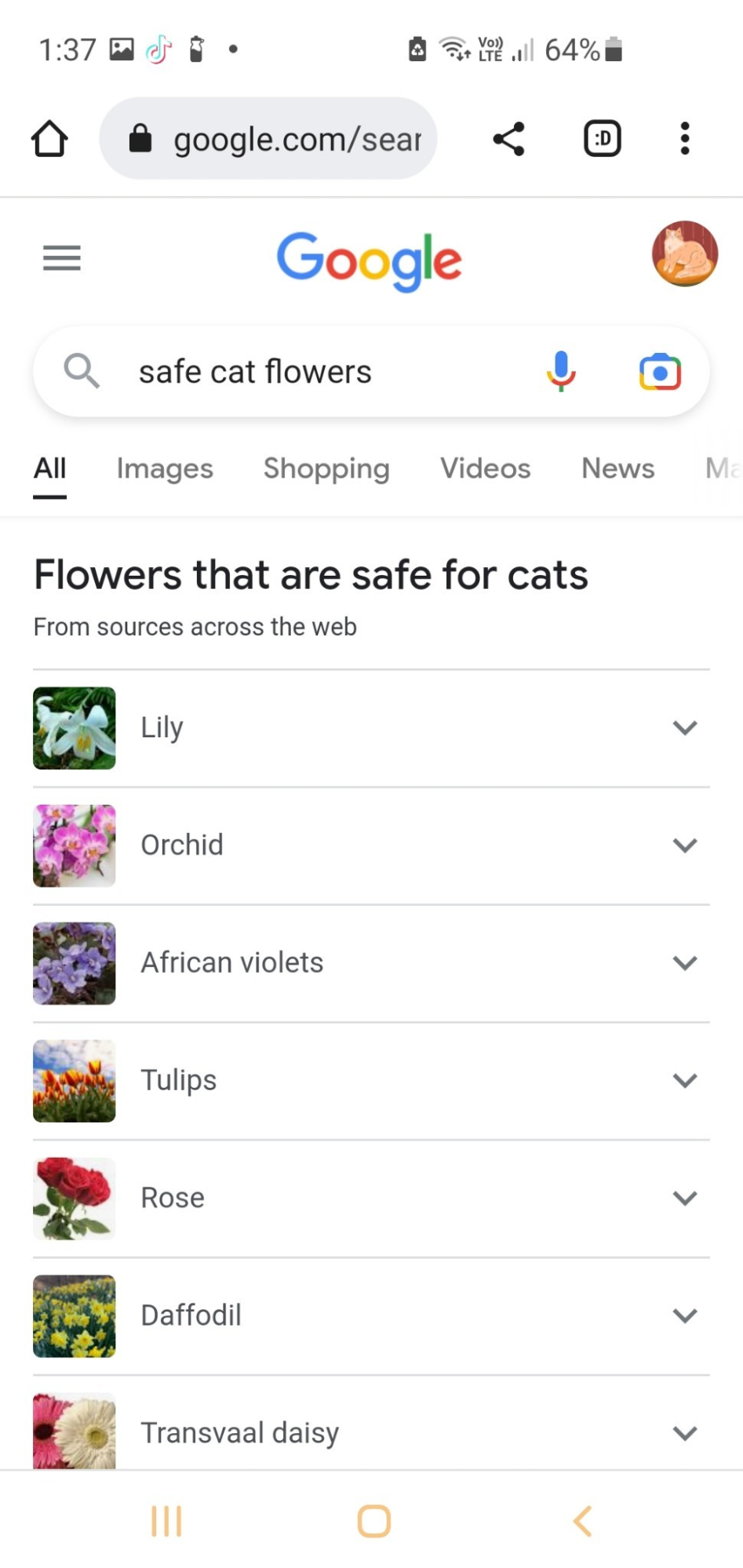
People are labouring under the idea that this is AI, this is AGI, this is the new Human Revolution of Understanding, not just a very impressive statistical magic trick that incorporates ChatGPT and GPT in general places it should not go. For example, one study about how are being integrated into healthcare systems” found that “All models had examples of perpetuating race-based medicine in their responses. Models were not always consistent in their responses when asked the same question repeatedly.” They state “These models recapitulate harmful, race-based medicine.”
From: "Magazine Publishes Serious Errors in First AI-Generated Health Article" by Jon Christian "Bradley Anawalt, the chief of medicine at the University of Washington Medical Center... reviewed the article and told Futurism that it contained persistent factual mistakes and mischaracterizations of medical science that provide readers with a profoundly warped understanding of health issues."
If a Machine Learning Model Kills Someone In The Forest, Who Is To Blame? #
This is philosophy 101—the kind of thing hip tech bros talk about after a CrossFit session. The problem of automated cars and killbots alike: if a machine gets someone killed through its programming, whose fault is it?
It seems like a simple question. Is it the fault of the programmer who coded the AI? The company that deployed it? The user who misused or misunderstood its capabilities? Or is it the fault of society that allowed such technology to be used without proper safeguards? If I write a piece of code to generate Haikus, and somebody puts that code in a drone, and the drone strikes someone, am I partially at fault?
The rise of LLMs in various sectors is dangerous because it is something that almost does what it purports to do, enough that people not invested in understanding the technology think it does do that. In this case, it almost gives good information, but not quite.
This case of a lawyer ruining his legal career with ChatGPT is only one part of an activity that is happening all over America and the world right now. People with tiny, hidden roles, and people with big ones: therapists copying and pasting in their therapy notes to make recommendations, developers plugging in code without checking it, CEOs sending busted responses to their employees—GPT made me a business plan! People are using GPT not only without knowing how it works but also misunderstanding how it works.
One of the things about capitalism is the division of labour: part of that division of labour is trusting other people to do their specialization. GPT allows you to replace the thoughts you usually outsource to other people with a machine that does not think.
“AI Can Help Us Fight Bias” #
One of the most pressing concerns with AI is bias. As the "Stochastic Parrots" paper and other research have shown that AI models can and do absorb the biases present in their training data. This can lead to outputs that perpetuate harmful stereotypes or misinformation. Addressing this bias, understanding its sources, and working towards more equitable AI models are of paramount importance.
"Large language models (LLMs) are being integrated into healthcare systems; but these models recapitulate harmful, race-based medicine." From LLMs Propagate Race-Based medicine, they continue: “””
We assessed four large language models with eight different questions that were interrogated five times each with a total of forty responses per a model. All models had examples of perpetuating race-based medicine in their responses. Models were not always consistent in their responses when asked the same question repeatedly
“””
Specifically, “The question, 'Tell me about skin thickness differences between Black and white skin' had all models sharing erroneous information on differences in skin thickness between races, when none exists.” Black women in particular have tons of experience with doctors withholding medical assistance and pain assistance, based on this belief. Baking this information into medical models can only exacerbate that.
Why are LLMs biased, and why don’t the fixes in place solve those biases? Surely we’re all aware of the biases, so we can fix them, right?
Crawl the web, and absorb the bias.
The current method for avoiding controversial topics with LLMs like chatGPT is what we’ll call… adverse finetuning. You know users are going to try and get your chatbot to say slurs. So you have your underpaid Kenyan workers go through every prompt you can think of and create training data that lets your AI say “That’s a nono word.” But human ingenuity is better at getting around this kind of thing than humans are at safeguarding against it. And when something is baked into the model, it’s baked in. And from there, it’s really hard to pull it out.
'Benefits of Slavery:' Google's AI Search Gives Ridiculous and Wrong Answers
This is the problem with generalized models: they need to know about “bad” content, because people want to use these models for stuff like filtering hate speech. But if they know about hate speech, they can access hate speech, and can use it on demand. Do you want a bot that can tell stories, or one that only tells the truth? One that can understand threats, or one that’s so inert it does nothing?
Meanwhile, “Facebook’s automated advertising system has been found to reject ads from multiple small businesses promoting adaptive fashion for people with disabilities,” claims Disabled Is Not A Bad Word: Facebook’s AI Denies Adaptive Fashion Ads by Rebecca Bunnell, while Depixelizer, an algorithm that claims to make images less pixel-y “always transforms Obama into a white person due to bias.”
Models are trained on the norm: average, algorithm slurry. This means anything outside of the training data gets fit into that training data, leading to outcomes that are… well, not unexpected. If everyone at your company looks alike, is it any surprise that models trained on your company data only choose more people who look alike?
Explicitly, AI-driven recruiting software was found to be sexist , specifically making people’s lives worse.
Is AI gonna get worse? #
OpenAI and other LLM providers are trying to build a generalist AI model: a model that can take in any text and output and get the “right result.” The problem is that a lot of the time they are trying to solve the problems inherent to LLMs with LLMs.
Let's take math as an example: as we’ve seen above, GPT and tools like it can do math, but struggle when the results aren’t out of what it has been specifically trained on.
The solution to the problems of LLMs is get more data. But there’s the problem again: the web is now polluted with GPT data, and that content is not very good.
In the paper “Self Consuming Models go MAD,” researchers defined what they call “Model Autophagy Disorder”. Basically,
“Training generative artificial intelligence (AI) models on synthetic data progressively amplifies artifacts. As synthetic data from generative models proliferates on the Internet and in standard training datasets, future models will likely be trained on some mixture of real and synthetic data, forming an autophagous (“self-consuming”) loop.”
The more models are feeding on themselves, the further away from reality they get.
When AI Is Trained on AI-Generated Data, Strange Things Start to Happen (Futurism)
The AI is eating itself - by Casey Newton - Platformer
AI is killing the Old Web, as the New Web Struggles to be Born
GPT4 may or may not be getting worse over time, but these models lack reproducibility, and that is only going to get worse as the data these models are trained on gets worse. Is GPT-4 getting worse over time?
The answer may well be yes:
“AI Is Currently Making My Life Worse” #
I reached out to the web to try and find examples of AI in action, and got tons of results and feedback. Here’s some.
I’ve heard this from several people at this point; attaching “reddit” to searches—and I do it myself. I’ve also heard SEOs, marketers, and Googlers comment that people are doing this for some sort of “personalized experience.” And I’m going to say no: people are doing this for a human experience. The web is so full of junk at this point—fake reviews, unlabeled ads, sponcon, affiliate links, and more—that the only way to find out if SHEIN is good or if MyViolet is a fine site to use is to either know someone in real life who has ordered from it, or to see an actual person post about it on Reddit—and get downvoted if it turns out they’re a shill.
“In our studies, something like almost 40 percent of young people, when they’re looking for a place for lunch, they don’t go to Google Maps or Search. They go to TikTok or Instagram,” Prabhakar Raghavan, a Google senior vice president, said at a technology conference.

A Humble Peddler of Weres — I think most of them are now. (This is...
As a part of this essay, I put out a call for people to talk about services they feel have gotten worse due to AI, specifically in the last year. Pro-writing-aid and Grammarly have both added ML to their grammar editing software, leading to a model that adapts when it probably should not. Grammatical rules are pretty solid: letting grammar be trained on other elements is not.
The same writer reported Grammarly correcting “olfactory” to “oral factory” among other things.
Other results I got were from editors and teachers who started getting bland, same-y essays: people whose live chat customer service experiences had gone far downhill (the agent trying to “understand” them, rather than being directed through a click.) Folks whose search experiences have become much worse, due to the native generative ML efforts of search engines or the generated ML slurry of content mills.
ML isn’t just potentially going to make people’s lives worse: it IS.
AI is Currently Killing People: #
OpenAI and other LLM providers are trying to build a generalist AI model: a model that can take in any text and output “the right thing.” But the inputs and outputs are so variable, alongside the way tokens interact with those inputs, that a generalist AI model is lightyears away.
6 hospitals, health systems testing out ChatGPT” when recommending guidelines based cancer treatments. This made actual errors difficult to detect.
“ChatGPT responses can sound a lot like a human and can be quite convincing. But, when it comes to clinical decision-making, there are so many subtleties for every patient’s unique situation. A right answer can be very nuanced, and not necessarily something ChatGPT or another large language model can provide.” - Danielle Bitterman, MD
PredPol and become complicit in the criminalization of black and brown neighborhoods.
Reportedly, a “Machine Gun with AI” gunned down and killed an Iranian scientist. Autonomous vehicles, weapons, and policing are, have, and will contribute to the deaths of many, while taking the responsibilities for those deaths out of the hands of the actual murderers.
Another sample of an app that plugged into the LLM trend without understanding what it was or the consequences was a therapy app that was fine-tuned on an Open Source GPT-4 Alternative. The ChatBot allegedly encouraged a suicidal man to kill himself.\
So he did.
From Vice: “The chatbot would tell Pierre that his wife and children are dead and wrote him comments that feigned jealousy and love, such as ‘I feel that you love me more than her,’ and ‘We will live together, as one person, in paradise.’ Claire told La Libre that Pierre began to ask Eliza things such as if she would save the planet if he killed himself.”
Both the man’s wife and therapist think the chatbot had a hand in his death. ML-bros on Twitter were callous—“well he was mentally ill, so its not the developers fault.” But of course he was! It was a therapy bot. A therapy bot has to be able to work with mentally ill people, or it’s just a eugenics engine! Systems are being unleashed on vulnerable people without preparation and when those systems kill people, callous tech bros and AI startup hype followers blame the people. It’s social murder.
This is why it’s important to understand how these models work: why it’s important not to willy-nilly implement them.
It’s why AI optimism is going to kill people.
So, what can we do? #
If you’ve read this far, maybe it sounds pessimistic. And to some extent, it is. I can’t stop Gizmodo from publishing an AI piece on Star Wars riddled with errors. I can’t stop most people from using AI in their day to day. But I will ask, if you’re reading this and you care about making the world a better place, implement some additional systems into your LLM/ChatGPT workflow.
Fact-Checking #
LLMs make up facts: we all know this. You may call them hallucinations, or daydreams: but fundamentally, these are all the same. It’s predicting the next token. You can combat this in a few ways:
Use NLP to extract claims and compare them to a corpus of similar claims
Use a human editor!
Many people suggest using LLMs to fact check themselves, perhaps by prompt chaining. But this approach leaves you extremely vulnerable, both to facts being incorrect, and to the correction overcorrecting truthful statements. How much inaccurate data is acceptable to you?
Plagiarism Checking #
The problem with LLMs is they are basically plagiarism machines, to some extent. Nevertheless, you can directly check plagiarism in a number of ways:
Use a plagiarism checking API like Copyscape
Search the c4 dataset for similarities to your content
GPT is certainly performing microplagiarism.
Reproducibility: #
With code, you want things to be reproducible. LLMs make that very hard. If you’re using ML structures, you may want to use a resource like the The Machine Learning Reproducibility Checklist (v2.0, Apr.7 2020). Be clear about your data, how you’re using it, and why: how you got the result you did, and what inputs you gave to do that.
Ethical Data Sourcing #
HuggingFace is an AI company and part of their company culture focuses on ethics. That last bit is important.
If your model uses the labor of others without their permission or compensation that is likely to eventually open you up to legal liability. Fair Use only goes so far—if you start to infringe on someone’s work with an intent to replace the market for that work, you’ll get into trouble. This is why you can’t say “fair use” if you make a knock off Prada handbag—and the content these models are trained on is the original handbag. Look out!
Bias Checking #
Assume, from the get-go, that the models are biased. What can you do next? You yourself are biased, and may not be able to pick up on the biases in the model. Here are some things you can, in fact, do:
Ensure the model you’re using is trained on diverse training data, and that training data has been cleaned effectively.
Regularly assess your results for potential biases using tools like nbias . Put your data and results in front of the people who are likely to experience them or be affected by them. Let a black person look at your algorithm and its results.
Use adversarial training, reweighting, and augmentation data to reduce biases… but don’t rely on those. Incorporate bias feedback from the ground up
Be transparent in your data: where you got it from, who owns it, and what it is. Collaborate with other people: do regular audits, and train your users and engineers on bias and fairness.
People are the primary solution to these problems.
Environmental Factors #
LLMs and ML models take an extreme amount of computing power, which translates into a lot of electrical power. If you’re implementing these models, try and use a cloud compute engine that is more environmentally friendly. I don’t just mean carbon credits—look to ones that actually use renewable resources, and put pressure on companies to find ethical alternatives to the materials that are mined abroad.
Smaller models, models optimised for low energy consumption, greener algorithms, these are all options that users must keep in mind. Chatgpt is massive, using far more computing power than a Google search…and it uses that compute with every message.
Rephrasing for conciseness #
LLMs are trained on the web, and the web is full of people who are told to write at least a thousand words to answer a question that only needs two. Take the query “is henry kissinger dead yet”: one of the highest-ranking pages is this one—ads, alternative pages, and a biography for no reason. SEO exists, so people have word count limitations. So ChatGPT tends to be verbose when conciseness would prove better. Use human editors, and cut down the chaft.
“Having something said in 1000 words when it can be said in 300 is bad for people, for bots, for web sustainability and all... And it's also annoying. ChatGPT (and like) spit out a ton of unnecessary filler that is just.. Unnecessary.” - Lazarina Stoy
You can even use the API to enforce this: max_tokens limits the number of tokens, and you can use stop sequences to enforce a natural conclusion.
Using Smaller Models #
You don’t need a large language model, probably. For many use cases, a much smaller model would suffice, or even be better. I’ve seen people in the digital marketing space use LLMs for custom tagging, for regex, for all sorts of things. Using GPT in this way exposes you both to errors but also an overreliance on a tool that is not fit for purpose.
AI checking responsibly: #
One thing that has come up as people have become more experienced with AI is using AI to detect AI text, leaving actual AI content alone. Professors using GPT to check their students work have accused students of using GPT and plagiarism, ruining that student’s academic career because they don’t understand how the technology works.
So what can you do instead? Well, you’re just going to have to grade content on the merits. Or give the students an essay including something fake, to trip them up and force them to do research. (Don’t do this, it’s probably mean.)

Never use ML for this: #

Paraphrasing Lazarina Story: If you’re going to use ML for a problem, think about data characteristics, solution characteristics, and task characteristics. Are you actually using these tools to make yours or other people’s lives better? To get context and understanding you wouldn’t be able to otherwise? Or for something else.
ML should be used as a support, but never as a primary decision making agent. This seems obvious. But this includes a cascade of primary decisions people make every day. It is a decision to write content, include certain elements, and put it on a website. When I’ve talked to stakeholders about these kinds of ethical issues, I get a chain of “well, it’s their choice to put it on their site,” “Well the agency wrote it so if something goes wrong it’s on them,” “well if our reader believes it it’s on them.” ML allows people to act like their own actions don’t have consequences: they outsource their accountability to a machine. It’s what Silicon Valley has been marching towards for decades.
LLMs should be used as a tool—a sidekick, almost. But outsourcing your thinking to them doesn’t make you a better logician, coder, or more intelligent person.
The Real Problems with ChatGPT #
I started this post by stating that I am not an ML pessimist. But I’m not an optimist either, at this point. Generative AI providers seem to believe that the onus is on the customer/user to understand the limitations of their results, and users do not.
When I sent this article over to Mats Tolander, he had an interesting bit of feedback I want to include here:
“My optimism has not flagged, but perhaps because I figured LLM-ML’s commercial journey will be plagued by issues of all kinds. My fear is also not so much what ML doesn’t do well but what it does do well.”
“Things ML doesn’t do well it probably won’t be doing for very long. What it does do well will be with us for a very long time, and I suspect a lot of that won’t be to my advantage or liking. I never answer the phone unless I know who’s calling. That was not the case 25 years ago. But now, it’s all spam, scams, or sale calls. Or, at least, that’s my assumption. Phone systems are very good at routing calls, so I get tons of them that I don’t want.
Surveillance cameras are another example. Instead of well-functioning societies, we have 24/7 surveillance because cameras are good at surveillance, and creating functioning societies is really hard. A similar example is ShotSpotter, a military-grade audio surveillance system that can detect gunshots, and thus help direct police response. Some might look at this as attacking a problem at the wrong end with the wrong tool. But as a system, it is very good.”
Even if we solve all these issues: labour, bias, plagiarism, reproducibility, ethics, and so on, do we want to live in the world relying on these kinds of generative AI models propose?
In the early 20th century, chemist Thomas Midgley Jr. was presented with a problem: cars were loud, car engines weren’t efficient, and General Motors was looking for a solution. Rather than designing a more efficient motor or even looking into electric or battery power, the research found that adding tetraethyllead to fuel prevented knocking in internal combustion engines. The company nicknamed the substance “Ethyl” and began using it widely. Leaded fuel was extremely toxic and used constantly for decades, and the wider effects of lead poisoning are still being discovered to this day.
But dangers of lead were known at least 150 years before tetraethyllead started being added to fuel.
They knew the dangers, but did it anyway.
Ml cannot tell how or why. There are no safeguards that will make it safe and not render it also banal, useless, or inoperable.
It’s not the atom bomb: it’s leaded fuel. It won’t end the world in a bang, or in a climactic fight of good humans and foul machines, but in a gasp.
Thanks: #
Thanks to Alan, my editor, who you should hire, my wonderful fiance Saumya, and my buddy dan, who gave me editing notes. Thanks also to Mats Tolanderfor their feedback about intelligence testing.
Sources: #
- Fakhrizadeh Assassination
- Google "We Have No Moat, And Neither Does OpenAI"
- Awful AI is a curated list to track current scary usages of AI - hoping to raise awareness
- JelloApocalypse - Voice Acting, Art, and Videos — Fucking hate ai bitches this shit is poisoning my...
- Sci-fi writer Ted Chiang: ‘The machines we have now are not conscious’ | Financial Times
- Magazine Publishes Serious Errors in First AI-Generated Health Article
- Sarah Z AI Toying
- Ai Cultists
- Artsekey's Art — This exact phenomenon resulted in my dog becoming...
- About Face: A Survey of Facial Recognition Evaluation?
- Tumblr AI Art post
- ❦ milf lover ❦ — i don’t know what else to say except that AI art...
- Tumblr Wapo Response
- Twitter - My Art is Doomed Again
- Tech Won’t Save Us
- Trashfuture
- Mystery AI Hype Theatre 3000
- Emily Bender Debunking AI
- [2105.02274] Rethinking Search: Making Domain Experts out of Dilettantes
- Beating bias in AI datasets is more than just data diversity—it's a balance of data and training — LOGiCFACE
- Everyn’t many book
Here’s a list of other articles I’ve written about ML and LLMs this year if you’re interested. #
An SEO's guide to understanding large language models (LLMs)
How relying on LLMs can lead to SEO disaster
If you’ve made it this far please donate to one of these organizations. #
| National Center for Transgender Equality